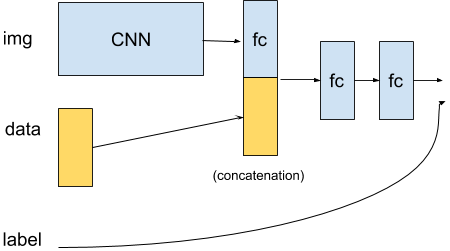
@Omegastick The example that I’m working on is a reinforcement learning example, using DQN. The observations from the environment are the visual camera input and the drone’s sensor reading. Since this is an end-to-end learning example, the inputs are the observations, and the outputs are the actions, with rewards guiding the agent’s learning process.
It is true, that for another example, I would use a CNN to do some sort of feature extract, like the location of a 3D waypoint marker. I could then concatenate the location of the way-point marker observation to the list I mentioned earlier. But for now, I am working on a simpler version of the problem, that is the next step after the standard DQN reinforcement example of only using visual inputs as the observations.
At the moment, I am trying to do something like this:
# concatenate observations
image = camera.processed_image
print("image.shape: {}".format(image.shape))
x, y, z, r, p, y = 1.1, 1.2, 1.3, 2.1, 2.2, 2.3
pose = [x, y, z, r, p, y]
sensor_range = [3.1]
obs = np.concatenate((image, pose, sensor_range), axis=0)
But I am having a problem with arranging the array dimentions correctly:
image.shape: (180, 320)
obs = np.concatenate((image, pose, sensor_range), axis=0)
ValueError: all the input arrays must have same number of dimensions