On a related note, this post by @ptrblck talks about concatenating a layer output with additional input data. I need to think and read a bit more, for what I need to do though.
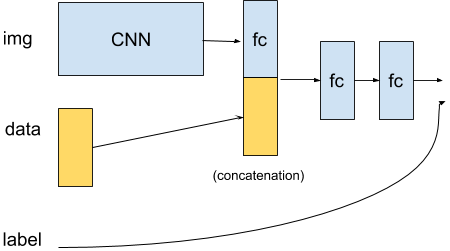
On a related note, this post by @ptrblck talks about concatenating a layer output with additional input data. I need to think and read a bit more, for what I need to do though.