Hi.
I’m using multiprocessing to train a model. I have two processes taking batches from queues (I’m actually using mp.Arrays that are more efficient, but a little trickier) and sharing my model weights.
Every ten batches seen, they make a validation iteration. In a trainBatch() method and in a valBatch() method, I placed calls to model.train() or model.eval(). They go something like this :
def trainBatch(model, input, criterion, target, optimizer):
optimizer.zero_grad()
model.train()
output = model(input)
loss = criterion(output, target)
loss.backward()
optimizer.step()
return loss
def valBatch(model, input, criterion, target):
model.eval()
with torch.no_grad():
output = model(input)
loss = criterion(output, target)
return loss
I’ve observed that without putting those calls, and therefore letting every iteration with train(True) (be it train or validation), the metrics are “rational”. But When I enable those calls, they become really weird, as can be seen here : (out_var and out_var_val are the variance of the logits, which I like to plot for diagnosis)
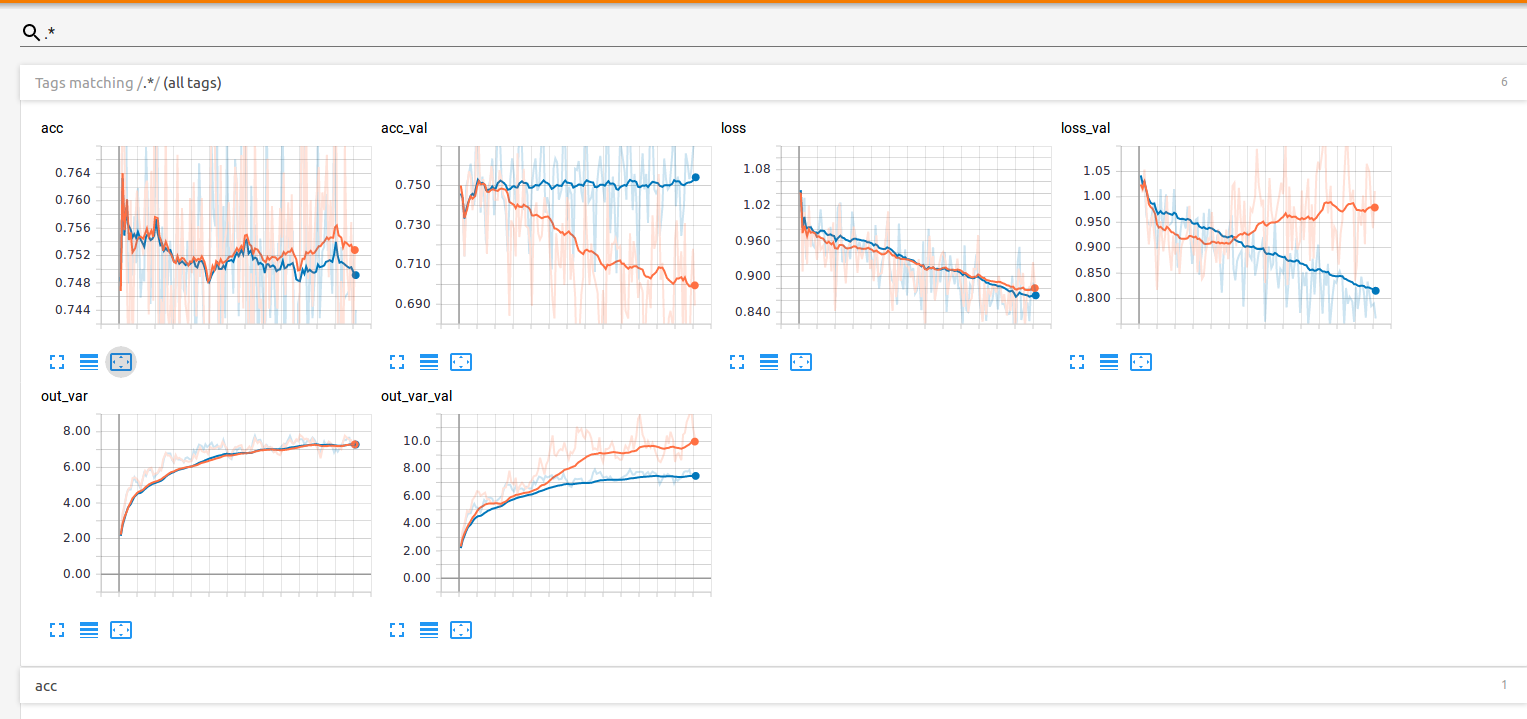
(orange : the curves while calling model.eval() and model.train(), and in blue without those calls)
I wonder if the problem doesn’t stem from the fact that, in such a framework, there can be a conflict on the layers with two opposite calls. Almost always : mode.eval() will be called while the model is doing a training iteration.
I wonder if this doesn’t screw the training of BatchNorm layers entirely, since the metrics in validation seem to be so poor. Or maybe, calling model.eval() while a training is happening deactivates the BatchNorm entirely without altering the learning ?
What do you think is happening ? Is validation during training prohibited in multiprocessing ?
 so a bit tedious for my work !
so a bit tedious for my work !