import os, re, sys, time
import numpy as np
from concurrent.futures import ProcessPoolExecutor
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
os.environ['CUDA_VISIBLE_DEVICES'] = ','.join(['0', '1', '2', '3'])
class Model(nn.Module):
def __init__(self, params=None):
super().__init__()
input_shape = params.get('input_size')
output_shape = params.get('output_size')
self.gru = nn.GRU(input_shape, output_shape, batch_first=True) # Note
def forward(self, x):
y = self.gru(x)
return y
# sub-process job
def single_job(cuda_id, params):
device = torch.device(cuda_id)
model = Model(params)
model.to(device)
for _ in range(1000):
X = torch.rand(4096, 16, 64).float()
X = X.to(device)
y_pred = model(X) # Note
time.sleep(1)
# main process
with ProcessPoolExecutor(max_workers=2) as executor:
for i in [1, 2]:
cuda_id = f'cuda:{i}'
params = {'input_size': 64, 'output_size': 1}
sub = executor.submit(single_job, cuda_id, params)
However, when it runs, the GPU occupation could be weird as shown below.
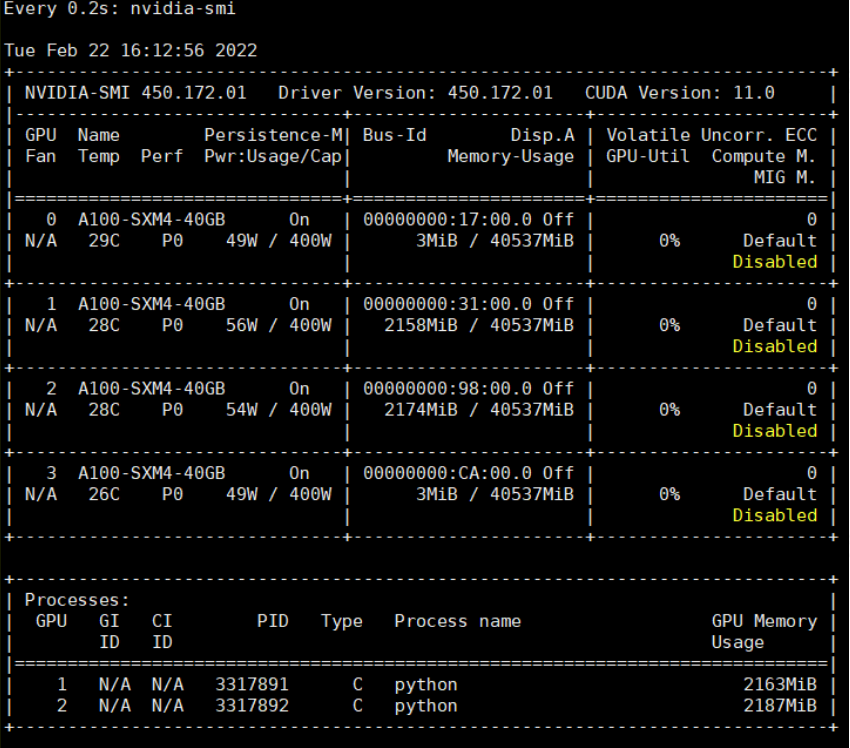
At the begining, the gpu occupation shown in nvidia-smi page is normal, with gpu 1 and 2 are occupied separately.
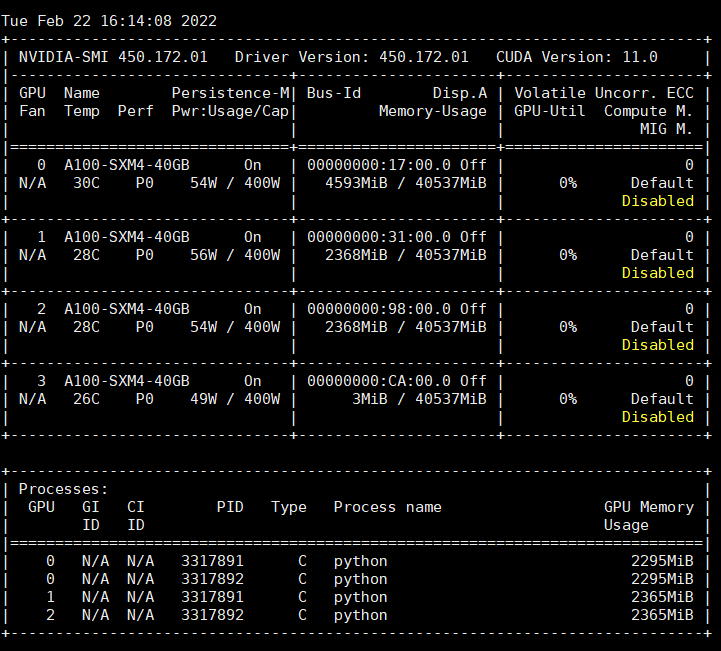
But after a few seconds, another two process is generated and occupy gpu 0 unexpectedly.
This problem is only caused by GRU layer (including other RNN layer) in model propagation as shown in the source code above.
The code runs correctly with torch-1.7 and corresponding cuda version.