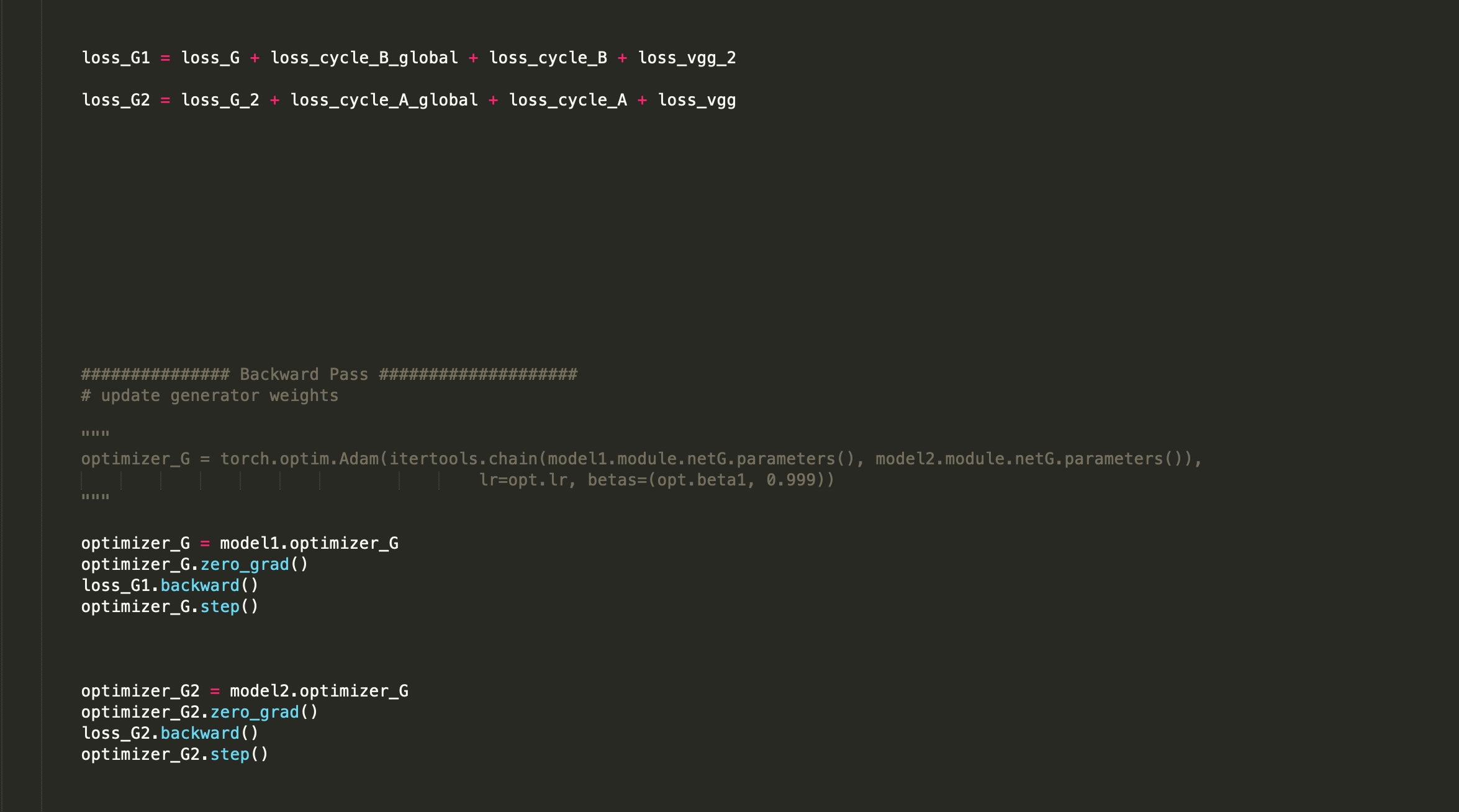
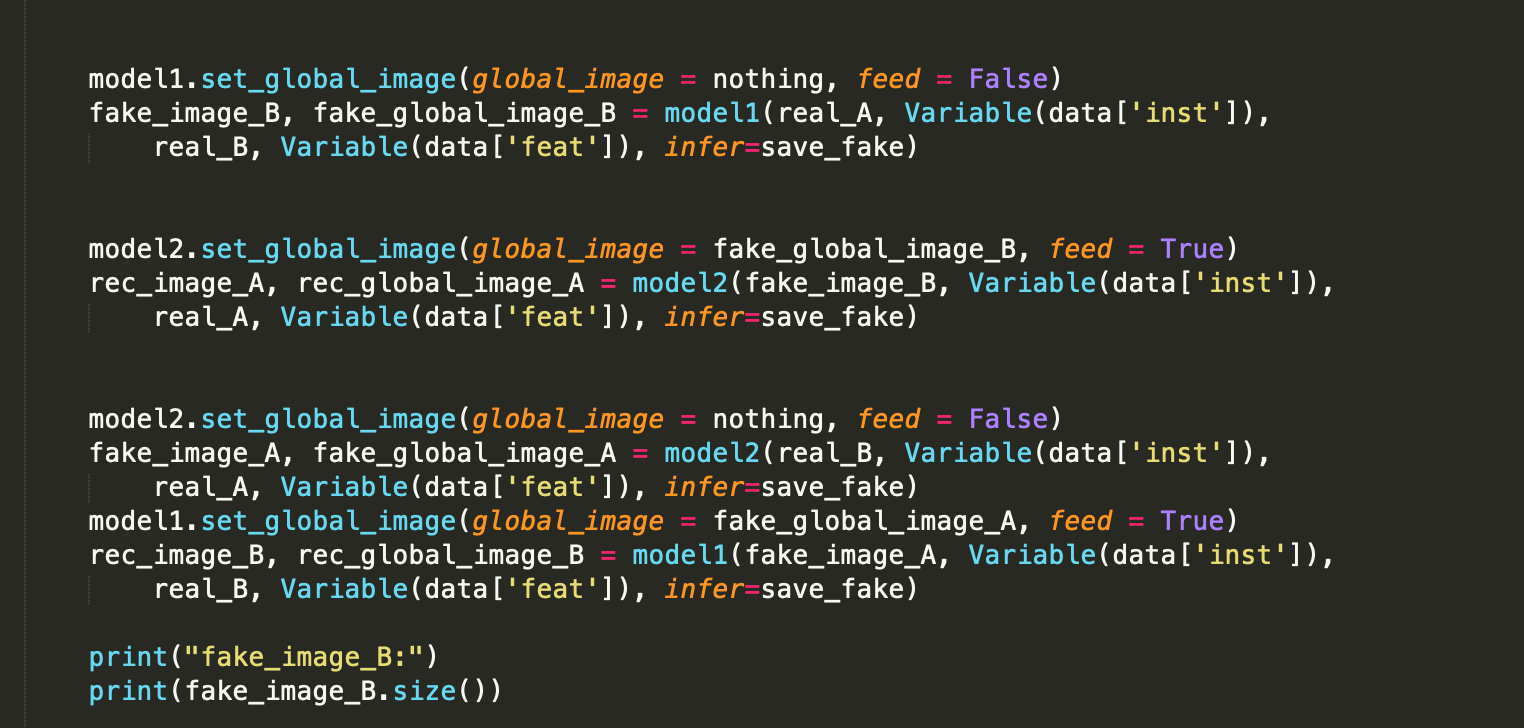
I am attempting to backward the loss on each different model. However, there is bug that stated
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.
From my understanding, I have placed the 2 models on separate GPU and the losses are defined separately, why is there still a bug like this…
The following is my code snippet
I guess model2 will get the output of model1 as its input?
If so, this behavior is expected, since loss_G1.backward() will clear the intermediate activations in model1, which are necessary to calculate the gradients using loss_G2.backward().
Could you explain your use case a bit?
If you don’t need gradients in model1 w.r.t. loss_G2, you could simply detach model1's output before passing it to model2.
Yes, the input and output are intertwined in some way, should I detach fake_global_image_A,fake_global_image_B, fake_image_A, fake_image_B separately.
Also, I am confused with the use of the Variable and tensor. In some implementation, some of the input data, such as the training data are transformed into Variable(like this one) instead of tensor. I am wondering why this is case. Since there does not seem to be a need to update the training data right?
Sorry for this messy post.
Variables are deprecated since PyTorch 0.4.0, so you can just use tensors instead.
You should detach the tensors coming from your generator, which should not create gradients in the generator. In a vanilla GAN setup you don’t want gradients in your generator while training your discriminator with the real target.
I’m not familiar with the architecture you would like to implement, but the DCGAN example might be a good reference.