I’m trying to utilize my training/testing of my model using 4 GPUs by testing with a very simple CNN:
class SimpleCNN(nn.Module):
def __init__(self, byte_size):
super(SimpleCNN, self).__init__()
self.l1 = nn.Sequential(nn.Linear(byte_size, int(byte_size/2)), nn.ReLU())
self.l2 = nn.Sequential(nn.Linear(int(byte_size/2), int(byte_size/4)), nn.ReLU())
self.l3 = nn.Sequential(nn.Linear(int(byte_size/4), 6))
def forward(self, x):
out = self.l1(x)
out = self.l2(out)
out = self.l3(out)
return out
And utilizing this tutorial on moving my model to multiple gpus tutorial:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SimpleCNN(BYTE_BLOCK_SIZE)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = nn.DataParallel(model)
model.to(device)
loss_function = nn.NLLLoss() # This is a convex loss function
optimizer = torch.optim.Adam(model.parameters(), lr=.03)
I get the following error (full trace):
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-86-3548497e2569> in <module>
6 print("Let's use", torch.cuda.device_count(), "GPUs!")
7 model = nn.DataParallel(model)
----> 8 model.to(device)
9
10 loss_function = nn.NLLLoss() # This is a convex loss function
~/anaconda3/lib/python3.8/site-packages/torch/nn/modules/module.py in to(self, *args, **kwargs)
850 return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
851
--> 852 return self._apply(convert)
853
854 def register_backward_hook(
~/anaconda3/lib/python3.8/site-packages/torch/nn/modules/module.py in _apply(self, fn)
528 def _apply(self, fn):
529 for module in self.children():
--> 530 module._apply(fn)
531
532 def compute_should_use_set_data(tensor, tensor_applied):
~/anaconda3/lib/python3.8/site-packages/torch/nn/modules/module.py in _apply(self, fn)
528 def _apply(self, fn):
529 for module in self.children():
--> 530 module._apply(fn)
531
532 def compute_should_use_set_data(tensor, tensor_applied):
~/anaconda3/lib/python3.8/site-packages/torch/nn/modules/module.py in _apply(self, fn)
528 def _apply(self, fn):
529 for module in self.children():
--> 530 module._apply(fn)
531
532 def compute_should_use_set_data(tensor, tensor_applied):
~/anaconda3/lib/python3.8/site-packages/torch/nn/modules/module.py in _apply(self, fn)
550 # `with torch.no_grad():`
551 with torch.no_grad():
--> 552 param_applied = fn(param)
553 should_use_set_data = compute_should_use_set_data(param, param_applied)
554 if should_use_set_data:
~/anaconda3/lib/python3.8/site-packages/torch/nn/modules/module.py in convert(t)
848 return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None,
849 non_blocking, memory_format=convert_to_format)
--> 850 return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
851
852 return self._apply(convert)
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Note that when using the model only on the CPU the code works fine and I’m able to easily train the model with no warnings/errors.
Then I checked this post because they had a similar error and when I did
import os
os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
torch.rand(1).cuda()
I still get the error:
RuntimeError Traceback (most recent call last)
<ipython-input-91-e97f59385399> in <module>
1 os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
----> 2 torch.rand(1).cuda()
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
So I couldn’t get a proper stacktrace even when CUDA_LAUNCH_BLOCKING=1 .
This was all done in Jupyter Notebook by the way. But what is even more weird is if I run the exact code above I do NOT get any error:
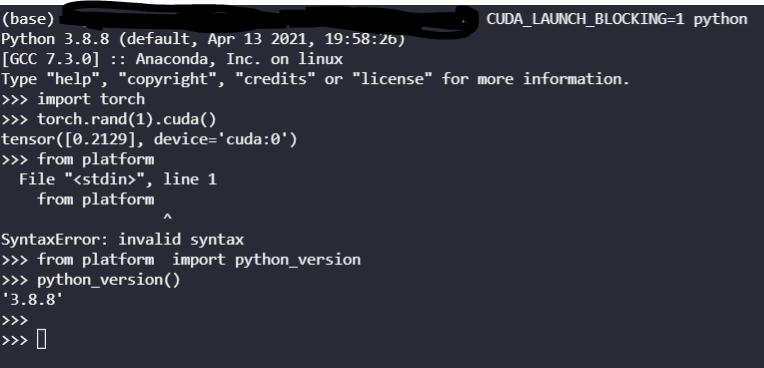
Is this a problem with my CUDA version? On my system I have CUDA 11.2 but I installed cuda toolkit=10.2 with Pytorch and I thought that Pytorch would use the cuda toolkit installed with Pytorch within Conda?
