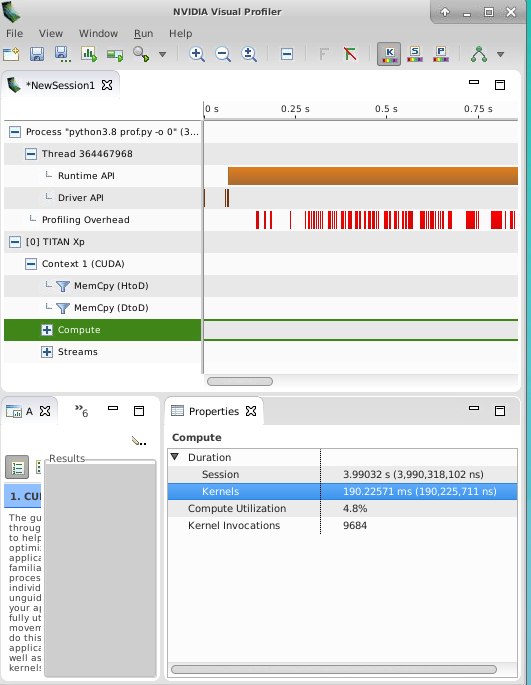
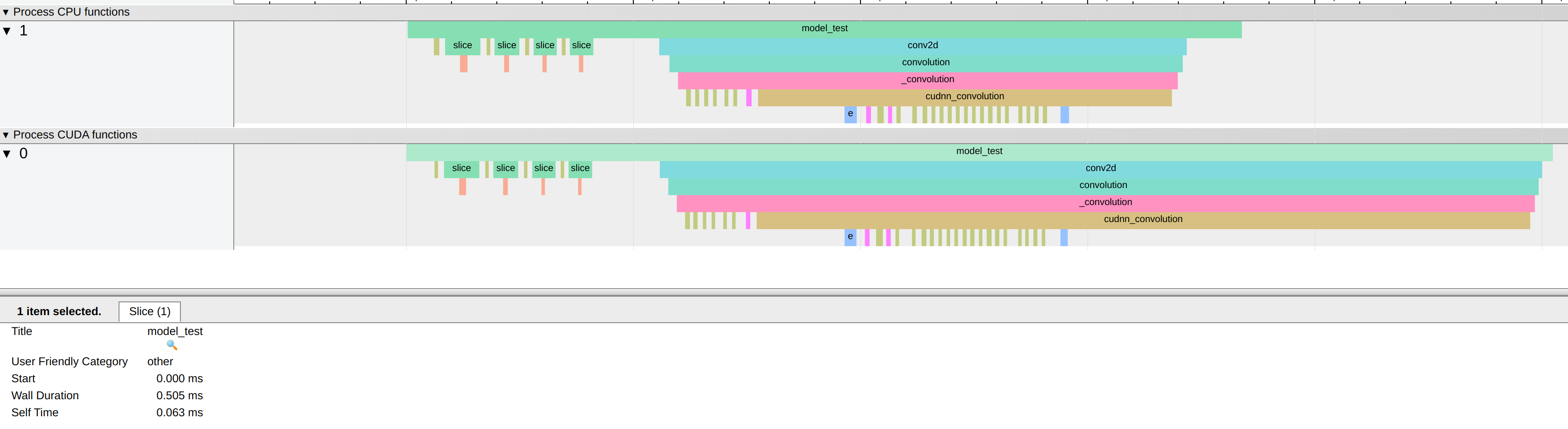
And I expect them to give same or at least very close profiling results, but they actually didn’t. Below are my snippet for profiling and results I got.
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-o', '--option', default=1, type=int)
args = parser.parse_args()
data = torch.randn(1, 3, 224, 224).cuda()
net = resnet18().cuda()
net.eval()
# Warm up run
for _ in range(10):
net(data)
if args.option == 0:
for _ in range(100):
out = net(data)
elif args.option == 1:
# Profiling 1
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
timing = 0
for _ in range(100):
start.record()
out = net(data)
end.record()
torch.cuda.synchronize()
timing += start.elapsed_time(end)
print(timing)
elif args.option == 2:
# Profiling 2
with torch.autograd.profiler.profile(use_cuda=True) as prof:
for _ in range(100):
net(data)
print(prof.key_averages().table(sort_by='cuda_time_total'))
elif args.option == 3:
# Profiling 3
with torch.autograd.profiler.profile() as prof:
for _ in range(100):
net(data)
print(prof.key_averages().table(sort_by='cpu_time_total'))
torch.util.bottleneck API
python -m torch.utils.bottleneck prof.py -o 0
CPU mode ...
Self CPU time total: 218.316ms
CUDA time total: 0.000us
CUDA mode ...
Self CPU time total: 207.595ms
CUDA time total: 207.673ms
torch.autograd.profiler.profile API
python prof.py -o 3
CPU mode ...
Self CPU time total: 295.712ms
python prof.py -o 2
CUDA mode ...
Self CPU time total: 499.643ms !!!!!!
CUDA time total: 1.802s !!!!!!
My question is why there is such a big profiling time discrepancy when I use torch.autograd.profiler.profile(use_cuda=True)?
Could you add synchronizations after the first CUDA call?
I’m not sure, if the autograd.profiler will accumulate the time needed for the CUDA context creation (and all other calls which were executed before and are not finished).
The CUDA time total is just sum of everything from table above. And I assume the operations in the table CUDA category are for compute. If it is for API call, then the time should fall under CPU time category right?
I also met a similar problem: The profiling result is quite different from what I record manually and I dont know the exact meaning of “Self CPU time total/ CUDA time total”.
Yes, met the same problem. The difference is actually big from what the profiler printed and what I recorded using the following code:
with torch.autograd.profiler.profile(use_cuda=True) as prof:
with torch.autograd.profiler.record_function(“model_test”):
out_test = model_test(img)
print('test time is ', prof)
prof.export_chrome_trace(“/trace.json”.format(count))
I tested with model with only one conv layer, and did 1 batch warm up before this…
The printed prof gives me results:
Self CPU time total: 367.306us
CUDA time total: 2.113ms
whereas the record tracking log gives me:
cpu time is the same, but cuda time is so different. tracing log gives me:
Hi, I did put cuda synchronize before, is that enough?
but unfortunately, the difference between the tracing log and the printed report still big (only cuda total). It seems for me that in the printed report, the cuda total time just sum up all the items in the table without considering some of the processes are of subprocess of other processes(for example, the first item in the table is the whole inference time consumption). so it over-calculated the time. Does that make sense to you? thanks!
torch.cuda.synchronize(),
with torch.autograd.profiler.profile(use_cuda=True) as prof:
out_test = model_test(img)
print('test time is ', prof)