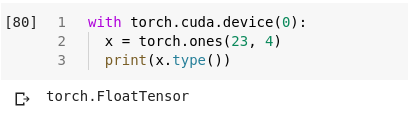
Hey folks,
I was wondering if someone could clarify some aspects of the cuda context manager.
For instance lets say we have dummy function, and we want to either send the whole function to cuda or whatever tensors are created/manipulated inside that dummy function to automatically get sent to cuda.
The torch.cuda.device() context is to change the defaut cuda device so that any cuda-related function will use that device.
We don’t have anything that forces all Tensors to move to cuda. This is mainly because this is a quite expensive operation and the user should be aware of it and avoid moving Tensors back and forth between the CPU and GPU.
I understand but think of the following scenario.
We have a model named net(inputs, targets) taking inputs and targets.
So far so good things are easy we can send net.to(device) and inputs.to(device), targets.to(device) accordingly.
Things start to get hairier when we want to manipulate some aspects of model as shown in the example above in def dummy_func.
Every torch.ones, torch.zeros whatnot has to be accompanied by .cuda.
Which most of the time will raise errors if we by mistake have at least one tensor that is on cpu and the rest on gpu and vice versa.
I think this defeats the purpose of model.to(device), does’t it?
We would expect that whatever is happening inside the model (whatever ops) to be sent to device, no?
to make sure you get a Tensor of the same type and same device as input.
If you have the same size (not the case for this example), you can do tmp = torch.ones_like(input) to get the same size/dtype/device.
You could do something like torch.set_default_tensor_type(torch.cuda.FloatTensor) but this is strongly advised against. Anything you will create will be on the GPU (temporary stuff for printing, internal buffers,…) and you most likely don’t want these on the GPU as ops on them will be much slower.