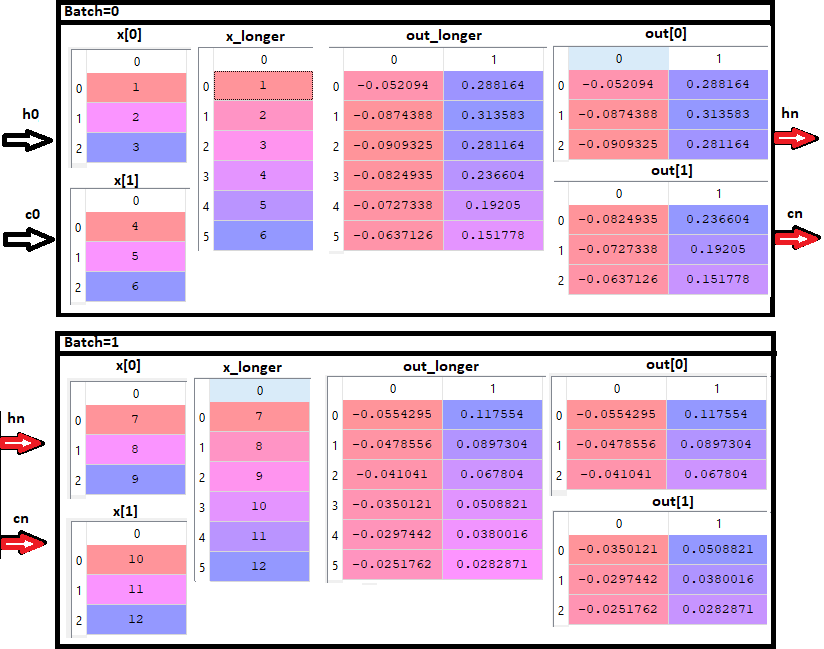
@amitp-ai Thank you for the information. I made a basic network trying to do what you propose for a LSTM stateful in pytorch. Could you tell me if this is what keras does??
import torch
# Custom Dataset
class TensorDataset(torch.utils.data.Dataset):
def __init__(self, TensorX,TensorY):
self.TensorX = TensorX
self.TensorY = TensorY
def __len__(self):
return self.TensorX.shape[0]
def __getitem__(self,idx):
return (self.TensorX[idx],self.TensorY[idx])
# Model = Stateful LSTM+linear
class LSTM(nn.Module):
def __init__(self, input_size,hidden_size,output_size):
super(LSTM, self).__init__()
self.lstm = torch.nn.LSTM(batch_first=True,input_size=input_size,hidden_size=hidden_size)
self.linear = torch.nn.Linear(in_features=hidden_size, out_features=output_size)
def forward(self, x, hn, cn):
# Stateful
x_longer = x.view(1,x.shape[0]*x.shape[1],x.shape[2])
out_longer, (hn, cn) = self.lstm(x_longer, (hn.detach(), cn.detach()))
out = out_longer.view(x.shape[0],x.shape[1],out_longer.shape[2])
out = self.linear(out[:,-1,:])
return out.unsqueeze(-1), (hn, cn)
N_epochs = 10000
hidden_size = 2
features = 1
learning_rate = 0.001
batch_size=2
output_size = 1
model = LSTM(input_size=features,hidden_size=hidden_size,output_size=output_size)#Create model
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate)#optimizer
criterion = torch.nn.MSELoss() # loss
# Create dataset: Imagine original_batch_size=2
x = torch.tensor([[1.0, 2.0, 3.0],[4.0, 5.0, 6.0],[7.0, 8.0, 9.0],[10.0, 11.0, 12.0]]).unsqueeze(-1)
y = torch.tensor([[4.],[7.],[10.],[13.]]).unsqueeze(-1)
dataset = TensorDataset(x,y)
dataloader = torch.utils.data.DataLoader(dataset,batch_size=batch_size)
# Training
for epoch in range(0,N_epochs):
# Create first hidden and cell state with batch=1
hn = torch.zeros(1, 1, hidden_size)#[num_layers*num_directions,batch,hidden_size]
cn = torch.zeros(1, 1, hidden_size)#[num_layers*num_directions,batch,hidden_size]
for x,y in dataloader:
optimizer.zero_grad()
out, (hn,cn) = model(x,hn,cn)
loss = criterion(out,y)
loss.backward()# Backward
optimizer.step()# gradient descent on adam step
I also did an in spyder debug for the first epoch, just to see the size of the tensors. I attach an image in case it is useful to someone else (the variable “out” is before using out = self.linear(out[:,-1,::]))