Hello,
I want to better understand the BatchNorm2D layer, so I am attempting to do a manual calculation but am unable to reproduce the results of BatchNorm2D. I have two issues: the first is with my understanding BatchNorm2D itself and the second is with regards to only running a subset of layers.
Problem 1: BatchNorm2D calculation
I am starting with the pretrained DenseNet121 and passing in a uniform image. Then I take the outputs of the 1st Conv2D layer and the 1st BatchNorm2D layer. I then take the statistics of the BatchNorm2D layer and try to use them to transform the outputs of Conv2D to get the same output.
mod = models.googlenet(pretrained=True)
#Generate a stimulus
stim = np.ones([224,244,3])
stims_t = np.moveaxis(stim[np.newaxis], -1, 1)
stims_t = torch.tensor(stims_t)
#Get statistics from the first BatchNorm2D
running_mean = mod.conv1.bn.running_mean.detach().numpy()
running_var = mod.conv1.bn.running_var.detach().numpy()
eps = mod.conv1.bn.eps
gamma = mod.conv1.bn.weight.detach().numpy()
beta = mod.conv1.bn.bias.detach().numpy()
#Get the output from just the first Conv2D
cnn = nn.Sequential(mod.conv1.conv)
out = cnn(stims_t.float())
out = out.detach().numpy().squeeze()
center = int(np.shape(out)[-1]/2) #I only want the output from the center convolution
conv1 = out[:,center,center]
#Get the output from the first BatchNorm2D
cnn2 = nn.Sequential(mod.conv1.conv, mod.conv1.bn)
out = cnn2(stims_t.float())
out = out.detach().numpy().squeeze()
center = int(np.shape(out)[-1]/2)
conv1_2 = out[:,center,center]
### Manual calculation ###
#(Attempt to) Transform Conv2D outputs into BatchNorm2D outputs
faux_conv1_2 = (conv1 - running_mean) / np.sqrt(running_var + eps)*gamma + beta
#Compare the true and faux normalizations:
plt.figure()
plt.plot(conv1_2)
plt.plot(faux_conv1_2)
plt.xlabel('Neuron')
plt.ylabel('Response')
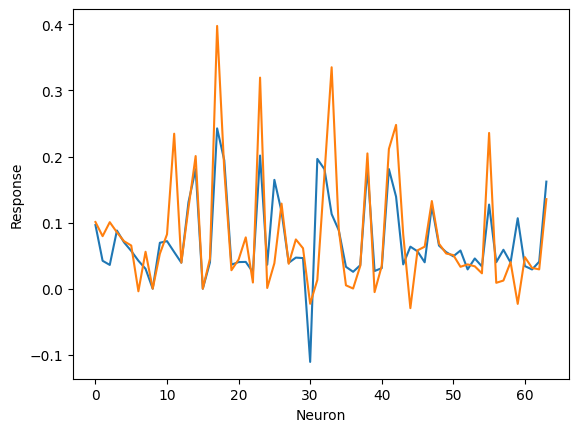
I would really appreciate anyone being able to tell me what is wrong with my calculation.
From my understanding of the documentation, any momentum calculations aren’t used during evaluation, and affine is set to True for DenseNet121, so I should be including gamma and beta.
Problem 2: Only running subset of layers via nn.Sequential
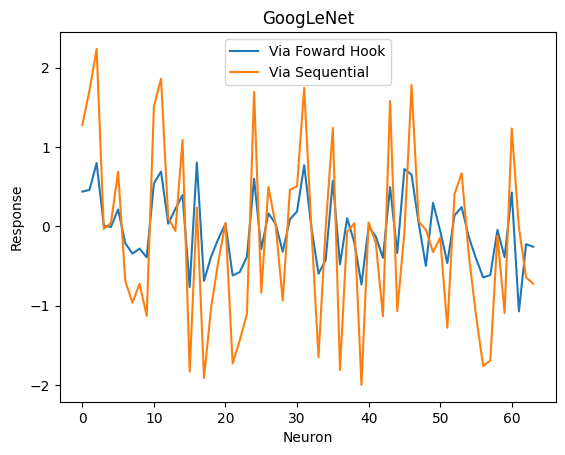
My second problem is related to the method I used to only run the first layers of DenseNet, wherein I took out the first few layers and put them back together with nn.Sequential. This method seems to work fine for DenseNet121 and AlexNet but fails for GoogLeNet when compared to using a forward hook. The main purpose of doing it this way to is to get the responses of intermediate layers while also not running the whole network. Is there something inherently wrong with my approach or am I missing something important about GoogLeNet?
#Define the hook
def hook(module,inp,output):
center = int(output.shape[-1]/2)
r_center = output[..., center, center]#just store responses from center of feature map
outputs.append(r_center)
#Generate a stimulus
stim = np.ones([224,244,3])
stims_t = np.moveaxis(stim[np.newaxis], -1, 1)
stims_t = torch.tensor(stims_t)
#For GoogLeNet (same method used in DenseNet and AlexNet)
mod = models.googlenet(pretrained=True)
for modl in mod.children(): #loop through every module
for layer in modl.children(): #loop through every layer in the module
if isinstance(layer, nn.Conv2d): #if it is a conv layer
layer.register_forward_hook(hook)
elif isinstance(layer, nn.ReLU):
layer.inplace = False #set inplace rectification to False to get unrect responses
mod2 = nn.Sequential(mod.conv1.conv) #replace with mod.features.conv0 for DenseNet121 or mod.features[0] for AlexNet
#Get response from forward hook method
outputs = []
r = mod(stims_t.float())
conv1 = outputs[0]
conv1 = conv1.detach().numpy().squeeze()
#Get response from Sequential method
out = mod2(stims_t.float())
out = out.detach().numpy().squeeze()
center = int(np.shape(out)[-1]/2)
conv1_2 = out[:,center,center]
print(conv1[0])
print(conv1_2[0])
The response of the first neuron via the forward hook is 0.43627724 while the response with nn.Sequential is 1.275382.
Thank you in advance!