test = torch.autograd.Variable(torch.randn([5,5]), requires_grad=True)
optimizer = torch.optim.Adam([test], lr = 0.0001)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=100, gamma=0.1)
lr_scheduler.get_lr()
This code snippet gives me a learning rate of 0.001
I want to start the optimizer with LR = 1e-4, and schedule a decay of 0.1 every 100 epochs.
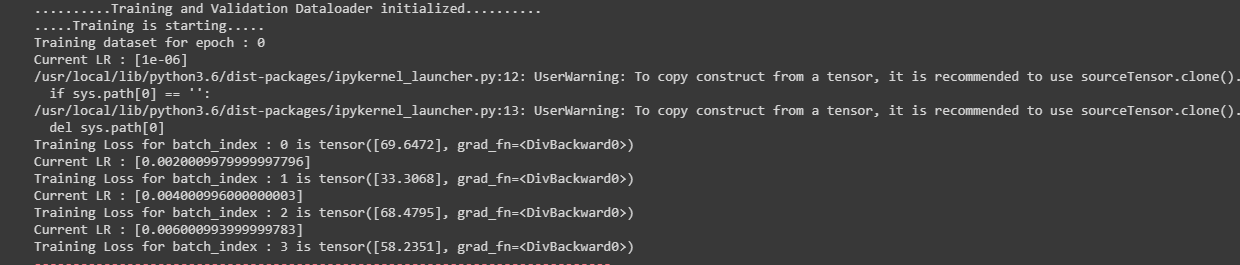
It seems like the LR Scheduler starts me off at 1e-3 instead.
Can someone clarify?
I am also finding the same issue while using lr scheduler. I want to start it from 1e-05 but it starts from 1e-03.
Another thing I found out that, if I increase the step size, then it will starts from 1e-04
Any one else got this issue. How they Solved it ?
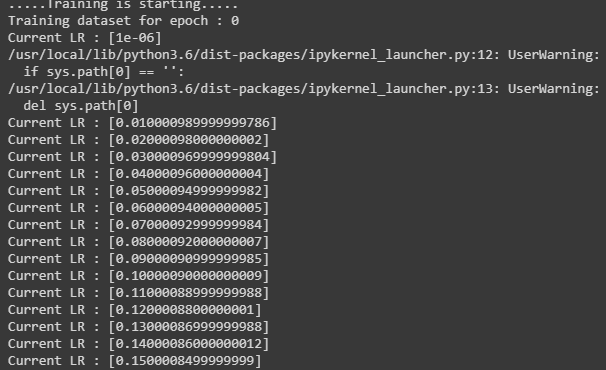
Correct me, If I am wrong. It is showing at the first print base_lr = 1e-06, when the lr scheduler is not called. After calling lr scheduler, it jumps to 0.01 and scaling with (+0.01). Rather it should starts from 1e-06 after calling lr scheduler and should scale accordingly.