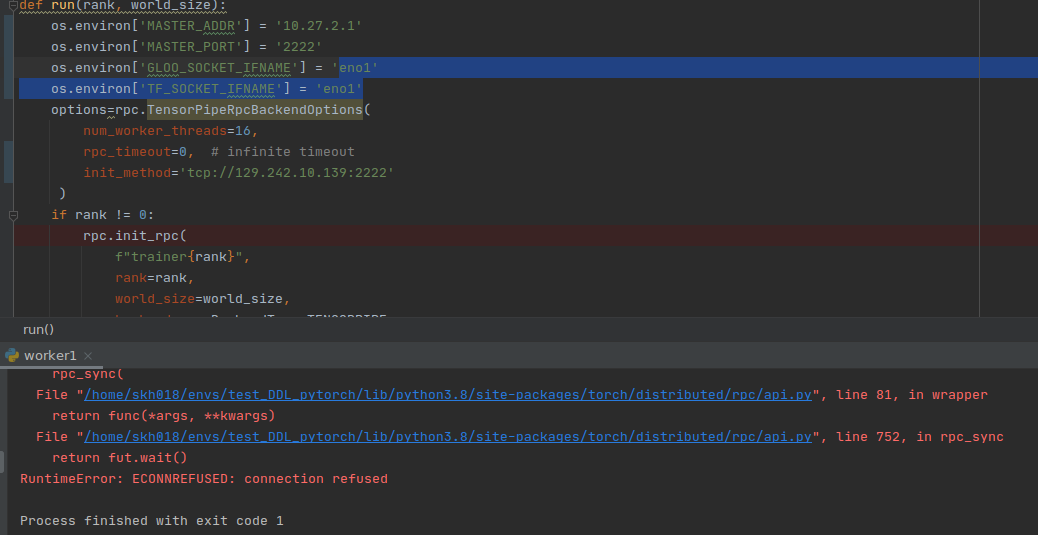
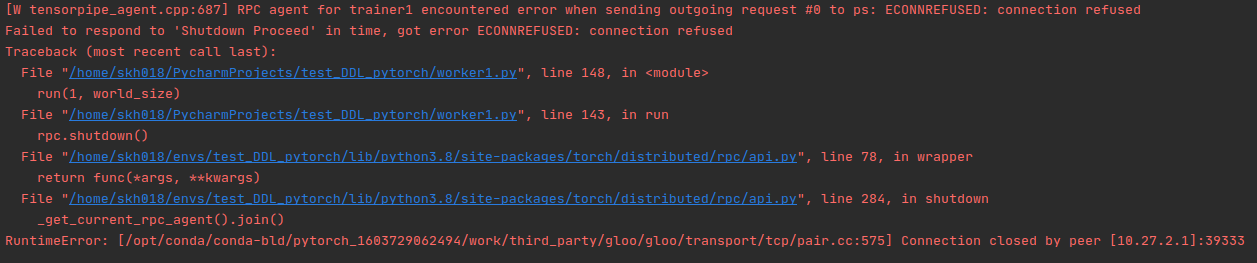
I am running this code on two machines. The code is same for both, but I run the run(rank,wordsize) function with rank zero and one (rank(0,2)). Each machine has two network interface and eno2 from PS is connected to eno1 in workser. So I change it in worker code to eno1 (einvroment variable).
import os
import threading
from datetime import datetime
import torch
import torch.distributed.rpc as rpc
import torch.multiprocessing as mp
import torch.nn as nn
from torch import optim
import torchvision
batch_size = 20
image_w = 64
image_h = 64
num_classes = 30
batch_update_size = 1
num_batches = 6
def timed_log(text):
print(f"{datetime.now().strftime('%H:%M:%S')} {text}")
class BatchUpdateParameterServer(object):
def __init__(self, batch_update_size=batch_update_size):
self.model = torchvision.models.resnet50(num_classes=num_classes)
self.lock = threading.Lock()
self.future_model = torch.futures.Future()
self.batch_update_size = batch_update_size
self.curr_update_size = 0
self.optimizer = optim.SGD(self.model.parameters(), lr=0.001, momentum=0.9)
for p in self.model.parameters():
p.grad = torch.zeros_like(p)
def get_model(self):
return self.model
@staticmethod
@rpc.functions.async_execution
def update_and_fetch_model(ps_rref, grads):
self = ps_rref.local_value()
timed_log(f"PS got {self.curr_update_size}/{batch_update_size} updates")
for p, g in zip(self.model.parameters(), grads):
p.grad += g
with self.lock:
self.curr_update_size += 1
fut = self.future_model
if self.curr_update_size >= self.batch_update_size:
for p in self.model.parameters():
p.grad /= self.batch_update_size
self.curr_update_size = 0
self.optimizer.step()
self.optimizer.zero_grad()
fut.set_result(self.model)
timed_log("PS updated model")
self.future_model = torch.futures.Future()
return fut
class Trainer(object):
def __init__(self, ps_rref):
self.ps_rref = ps_rref
self.loss_fn = nn.MSELoss()
self.one_hot_indices = torch.LongTensor(batch_size) \
.random_(0, num_classes) \
.view(batch_size, 1)
def get_next_batch(self):
for _ in range(num_batches):
inputs = torch.randn(batch_size, 3, image_w, image_h)
labels = torch.zeros(batch_size, num_classes) \
.scatter_(1, self.one_hot_indices, 1)
yield inputs.cuda(), labels.cuda()
def train(self):
name = rpc.get_worker_info().name
m = self.ps_rref.rpc_sync().get_model().cuda()
for inputs, labels in self.get_next_batch():
timed_log(f"{name} processing one batch")
self.loss_fn(m(inputs), labels).backward()
timed_log(f"{name} reporting grads")
m = rpc.rpc_sync(
self.ps_rref.owner(),
BatchUpdateParameterServer.update_and_fetch_model,
args=(self.ps_rref, [p.grad for p in m.cpu().parameters()]),
).cuda()
timed_log(f"{name} got updated model")
def run_trainer(ps_rref):
trainer = Trainer(ps_rref)
trainer.train()
def run_ps(trainers):
timed_log("Start training")
ps_rref = rpc.RRef(BatchUpdateParameterServer())
futs = []
for trainer in trainers:
futs.append(
rpc.rpc_async(trainer, run_trainer, args=(ps_rref,))
)
torch.futures.wait_all(futs)
timed_log("Finish training")
def run(rank, world_size):
os.environ['MASTER_ADDR'] = '10.27.1.1'
os.environ['MASTER_PORT'] = '49000'
os.environ['TF_SOCKET_IFNAME'] = 'eno2'
os.environ['GLOO_SOCKET_IFNAME'] = 'eno2'
if rank != 0:
rpc.init_rpc(
f"trainer{rank}",
rank=rank,
world_size=world_size,
backend=rpc.BackendType.TENSORPIPE,
)
# trainer passively waiting for ps to kick off training iterations
else:
rpc.init_rpc(
"ps",
rank=rank,
world_size=world_size,
backend=rpc.BackendType.TENSORPIPE,
)
run_ps([f"trainer{r}" for r in range(1, world_size)])
# block until all rpcs finish
rpc.shutdown()
if __name__=="__main__":
world_size = batch_update_size + 1
run(0,world_size) # Rank zero for PS and Rank 1 for Worker
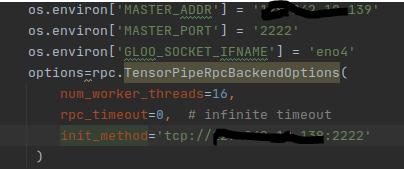
I add this option too the errors are same.
options=rpc.TensorPipeRpcBackendOptions(
num_worker_threads=16,
rpc_timeout=0, # infinite timeout
init_method='tcp://10.27.1.1:49000'
)
Worker error:
Failed to respond to 'Shutdown Proceed' in time, got error EHOSTUNREACH: host is unreachable
Traceback (most recent call last):
File "worker1.py", line 156, in <module>
run(1, world_size)
File "worker1.py", line 151, in run
rpc.shutdown()
File "/home/skh018/envs/distributed_learning/lib/python3.8/site-packages/torch/distributed/rpc/api.py", line 78, in wrapper
return func(*args, **kwargs)
File "/home/skh018/envs/distributed_learning/lib/python3.8/site-packages/torch/distributed/rpc/api.py", line 284, in shutdown
_get_current_rpc_agent().join()
RuntimeError: [/opt/conda/conda-bld/pytorch_1603729062494/work/third_party/gloo/gloo/transport/tcp/pair.cc:575] Connection closed by peer [10.27.1.1]:4482
PS error:
[W tensorpipe_agent.cpp:687] RPC agent for ps encountered error when sending outgoing request #0 to trainer1: ECONNREFUSED: connection refused
Traceback (most recent call last):
File "/home/skh018/PycharmProjects/distribbuted_learning_pytorch/test_DDL_pytorch/ps_new.py", line 157, in <module>
run(0,world_size)
File "/home/skh018/PycharmProjects/distribbuted_learning_pytorch/test_DDL_pytorch/ps_new.py", line 149, in run
run_ps([f"trainer{r}" for r in range(1, world_size)])
File "/home/skh018/PycharmProjects/distribbuted_learning_pytorch/test_DDL_pytorch/ps_new.py", line 110, in run_ps
torch.futures.wait_all(futs)
File "/home/skh018/envs/distribbuted_learning_pytorch/lib/python3.8/site-packages/torch/futures/__init__.py", line 162, in wait_all
return [fut.wait() for fut in torch._C._collect_all(cast(List[torch._C.Future], futures)).wait()]
RuntimeError: ECONNREFUSED: connection refused
For runing I just use:
python ps.py
python worker.py
I hope, I covered all details.
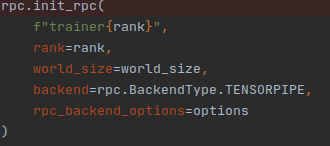
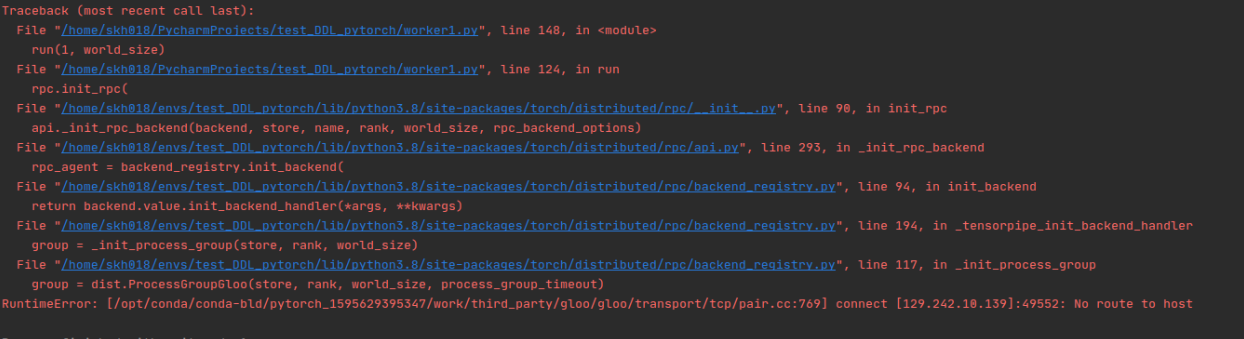
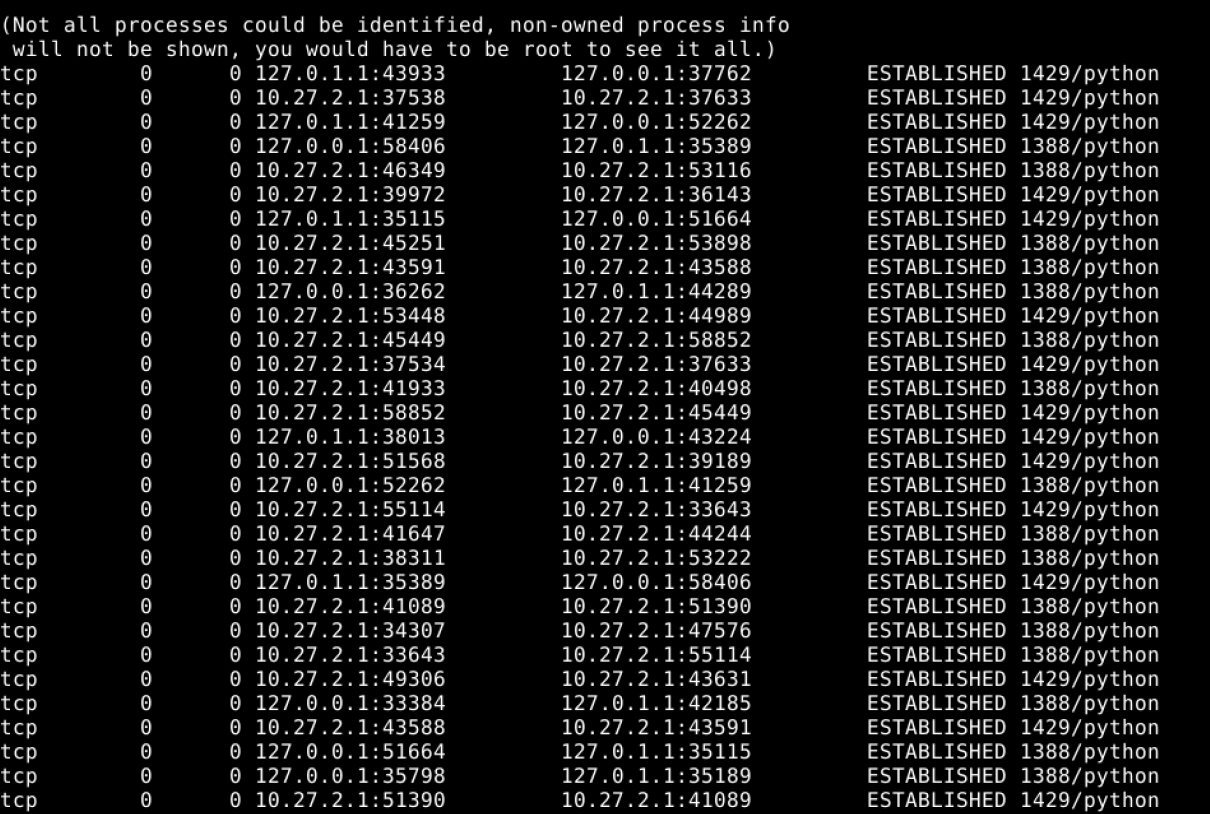
 and it seems these processes try to open and get connect after the first connection on a specified port.
and it seems these processes try to open and get connect after the first connection on a specified port.