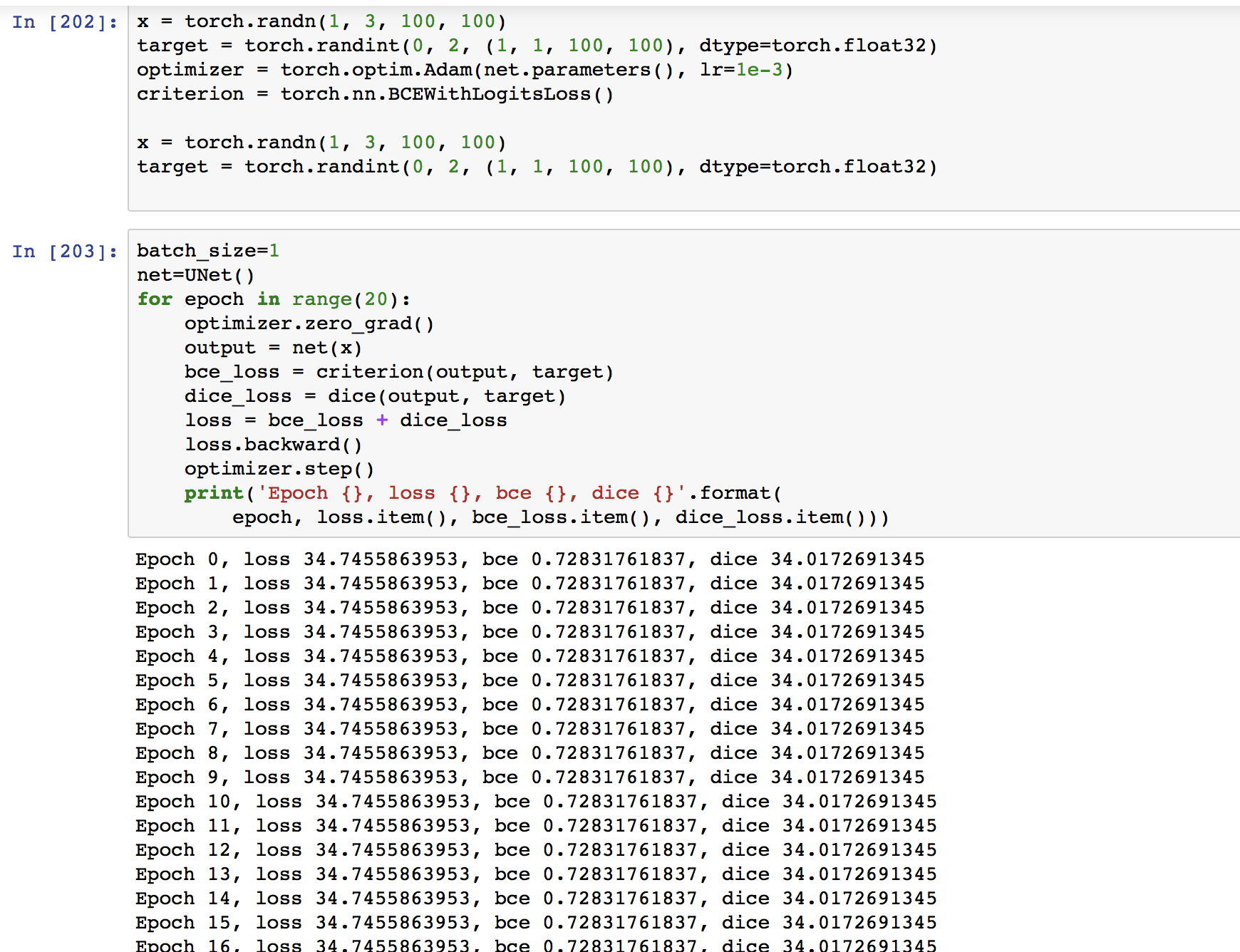
Hey, I am training a simple Unet on dice and BCE loss on the Salt segmentation challenge on Kaggle. My model’s loss is not changing at all. In this example, I pick a dataset of only 5 examples and keep interacting through and get a constant loss. My gradients are not getting backdroped I think, what can I do?
class DatasetSalt(Dataset):
def __init__(self, file_path='/Users/admin/deepschool.io/salt/images/*', transform=None,limit_paths=0):
self.path = glob.glob(file_path)
self.path=self.path[:limit_paths]
self.transform = transform
def __len__(self):
return len(self.path)
def __getitem__(self, index):
images = cv2.imread(self.path[index])
images=images[:-1,:-1,:]
images=torch.from_numpy(images)
images.transpose_(1,2)
images.transpose_(0,1)
mks='/Users/admin/deepschool.io/salt/masks/'+self.path[index][39:]
labels=cv2.imread(mks)[:-1,:-1,0]
sample={'image': images,'label': torch.from_numpy(labels)}
if self.transform is not None:
image = self.transform(image)
return sample
import torch.optim as optim
criterion = torch.nn.BCEWithLogitsLoss()
optimizer = optim.Adam(net.parameters(), lr=10)
def dice(input, taget):
smooth=.001
input=input.view(-1)
target=taget.view(-1)
return(1-2*(input*target).sum()/(input.sum()+taget.sum()+smooth))
batch_size=5
net=UNet()
def train():
list_dice=[]
cross=[]
dataset=DatasetSalt(limit_paths=5)
dataloader=DataLoader(dataset,batch_size, shuffle=True, num_workers=2)
for idx, batch_data in enumerate(dataloader):
inputs, labels=batch_data['image'].float(),batch_data['label'].float()
out=net(inputs)
BCE=criterion(out.view(batch_size,100,100),labels.float())
dice_loss=dice(out.view(batch_size,100,100),labels.float())
list_dice.append(dice_loss)
cross.append(BCE)
avg1=sum(list_dice)/len(list_dice)
avg2=sum(cross)/len(cross)
print(avg1[0].item(),avg2[0].item())# print average loss until now
loss=BCE+dice_loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
Output:
(0.7458401918411255, 0.568533182144165)
(0.7458400726318359, 0.5685329437255859)
(0.7458401322364807, 0.5685330629348755)
(0.7458401918411255, 0.5685333609580994)
(0.7458401918411255, 0.568533182144165)
(0.7458400726318359, 0.5685329437255859)
(0.7458401322364807, 0.5685330629348755)
(0.7458401918411255, 0.5685333609580994)
limit_paths just limits the dataset to a smaller size, I tried training on only BCE or dice and even changing lr form 10-0.0001 with no luck. The changes to the loss are very tiny. I trimmed the image from 101 101 to 100 100 to make my network symmetric for unet. I think the error may be the loss function. My mask is 101 101 while input 101 101 3