Hi,
I wonder if anyone has got A3C working with continuous actions? I guessed it would be a good idea to ask first before trying to do it, as there’s probably a good reason why no one’s got it to work yet?
I’m working on modifying, @Ilya_Kostrikov, implementation,
So for example Open AIs pendulum, as only got a state/observation vector of 3, so there’s no need for any conv’s in the Actor-Critic module, basically I’m trying,
lstm_out = 256
enc_in = 3 # for pendulum
enc_hidden = 200
enc_out = lstm_out
class ActorCritic(nn.Module):
def __init__(self , lstm_in ):
super(ActorCritic, self).__init__( )
self.fc_enc_in = nn.Linear(enc_in,enc_hidden) # enc_input_layer
self.fc_enc_out = nn.Linear(enc_hidden,enc_out) # enc_output_layer
self.lstm = nn.LSTMCell(lstm_in, lstm_out)
self.actor_mu = nn.Linear(lstm_out, 1)
self.actor_sigma = nn.Linear(lstm_out, 1)
self.critic_linear = nn.Linear(lstm_out, 1)
self.train()
def forward(self, inputs):
x, (hx, cx) = inputs
x = F.relu(self.fc_enc_in(x))
x = self.fc_enc_out(x)
hx, cx = self.lstm(x, (hx, cx))
x = hx
return self.critic_linear(x), self.actor_mu(x), self.actor_sigma(x), (hx, cx)
The initialisation code in main.py, then looks like,
env = gym.envs.make("Pendulum-v0")
lstm_in = 3
global_model = ActorCritic( lstm_in )
global_model.share_memory()
local_model = ActorCritic( lstm_in )
And the training code is where I get confused (as usual) ???,
env = gym.envs.make("Pendulum-v0")
s0 = env.reset()
done = True
state = torch.from_numpy(s0).float().unsqueeze(0)
value, mu, sigma, (hx, cx) = local_model((Variable(state), (hx, cx)))
#mu = mu.clamp(-1, 1) # constain to sensible values
Softplus=nn.Softplus()
sigma = Softplus(sigma + 1e-5) # constrain to sensible values
normal_dist = torch.normal(mu, sigma)
prob = normal_dist
log_prob = torch.log(prob)
entropy = 0.5 * (torch.log(2. * np.pi * sigma ) + 1.)
##--------------------------------------------------------------
# TODO Calculate the Gaussian neg log-likelihood, log(1/sqrt(2sigma^2pi)) - (x - mu)^2/(2*sigma^2)
# See - https://www.statlect.com/fundamentals-of-statistics/normal-distribution-maximum-likelihood
#
log_prob = torch.log(torch.pow( torch.sqrt(2. * sigma * np.pi) , -1)) - (normal_dist - mu)*(normal_dist - mu)*torch.pow((2. * sigma), -1)
##--------------------------------------------------------------
action = Variable( prob.data )
#action=[0,]
state, reward, done, _ = env.step([action.data[0][0]])
References,
Reference - Deepmind A3C’s paper, https://arxiv.org/pdf/1602.01783.pdf
Section 9 - Continuous Action Control Using the MuJoCo Physics Simulator
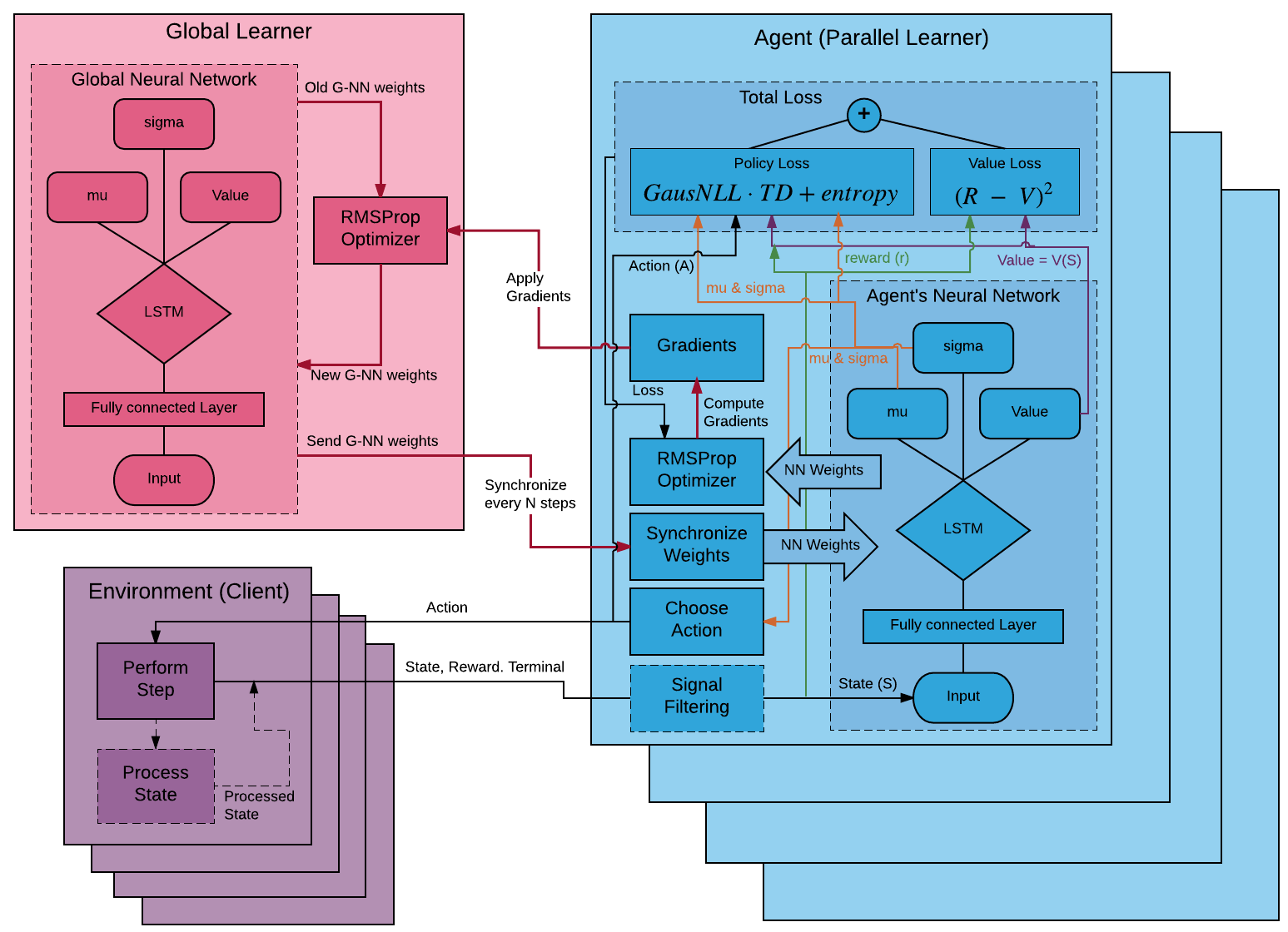
Here’s a diagram of the algorithm, from GitHub - deeplearninc/relaax: Reinforcement Learning framework to facilitate development and use of scalable RL algorithms and applications

{kind=link}