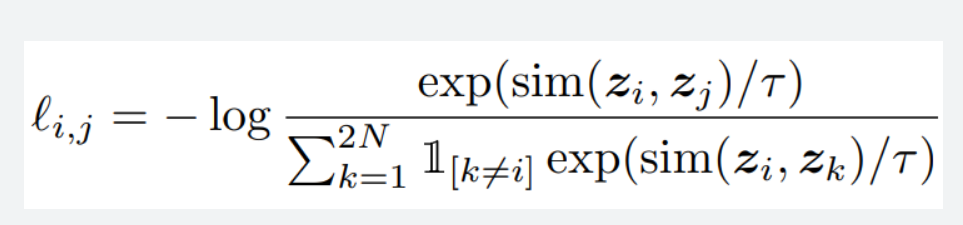When it comes to contrastive learning, the objective is to maximize the similarity between similar data points while minimizing the similarity between dissimilar ones.
One of the commonly used contrastive losses is the NT-Xent loss, where “Sim” represents the cosine similarity between two data point representations.
To minimize the loss, the numerator should be increasing, while the denominator should be decreasing. Since the denominator has “Sim” arguments, it has to decrease. The cosine similarity ranges from -1 to 1, and it seems that the closer the cosine similarity is to -1, the lower the loss becomes.
However, during my training process using this loss, I noticed that the similarity terms in the denominator converge to 0 instead of -1. (To be specific, sim(zi, zk) mentioned in the figure above)
Is there a mathematical explanation for this unexpected behavior?
Without knowing the details on how you obtain your latents z and what code you use to compute their cosine similarity, it’s really hard to tell what exactly caused this behavior.
A wild guess would be that you actually monitor the similarity after applying the exponential. If your model converges such that 0 < tau << 1 and sim(zi, zk) is approx. equal to -1, 0 would be the expected outcome in that case.
Actually, Mine is SimCSE and tau is a hyperparameter(=0.05)
(latent z can be obtained by passing through an encoder)
Sim(cosine_similarity) can get -1~1.
The problem is that Sim(zi, zk) converges to 0 while sim(zi, zj), the positive pair, goes to 1 as expected
And according to the loss formula, I think Sim should get close to -1.
I hope it makes sense.
If you have any opinion and share it, it would be very helpful to me.
Thanks