Currently doing contrastive learning on a dual-stream model with one XLM-RoBERTa and a CLIP-text model, loading the pretrained parameters and adding a new pooler for projecting [CLS], calculating with infoNCE loss.
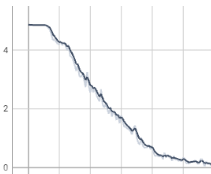
But as the loss curve shows, contrastive loss decreases drastically, reaching near 0 at about 2000 steps (sometimes even faster with larger lr), and if it keeps training, the loss will suddenly jump to about 4, I think it is caused by gradient explosion.
I’ve added autograd and scaler for fp16 training and I think it’s used correctly, here is a snippet.
def ttc_iter(model, batch, optimizer, scaler, metric_logger, device):
train_batch = [t.to(device) if t is not None else None for t in batch]
optimizer.zero_grad()
with autocast():
loss = model(train_batch)
scaler.scale(loss['loss_itc']).backward()
metric_logger.update(loss_mln_eng_ttc=loss['loss_itc'].item())
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
scaler.step(optimizer)
scaler.update()
return loss
I couldn’t figure out where the problem occurs, maybe somewhere in the model (since I have added additional encoder layers to the encoder structure)? Thanks for any suggestions in advance!