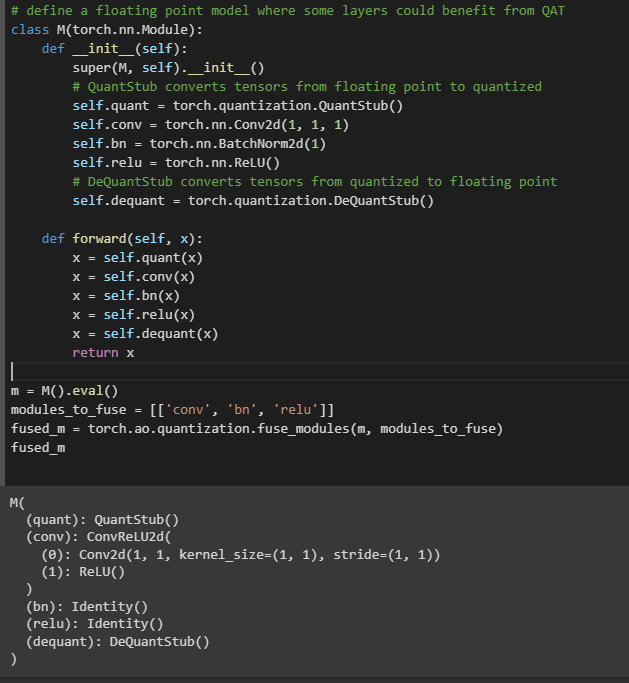
It seems is_qat arg for torch.ao.quantization.fuse_modules() defines state for training or evaluation. Since batchnorm layer not used for static quantization and will needed for QAT as far as I know, it’s internally merged into conv layer when QAT disabled. Here’s the quick summary:
a little code snippet from torchvision to apply proper fuse.
def _fuse_modules(
model: nn.Module, modules_to_fuse: Union[List[str], List[List[str]]], is_qat: Optional[bool], **kwargs: Any
):
if is_qat is None:
is_qat = model.training
method = torch.ao.quantization.fuse_modules_qat if is_qat else torch.ao.quantization.fuse_modules
return method(model, modules_to_fuse, **kwargs)
in line method = torch.ao.quantization.fuse_modules_qat if is_qat else torch.ao.quantization.fuse_modules shows us QAT fuse has different approach from default one.
>>> m # module itself
Conv2dNormActivation(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
>>> m.eval()
Conv2dNormActivation(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
>>> _fuse_modules(m, modules_to_fuse, is_qat=False)
Conv2dNormActivation(
(0): ConvReLU2d(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): ReLU()
)
(1): Identity()
(2): Identity()
)
>>> _fuse_modules(m, modules_to_fuse, is_qat=True)
Conv2dNormActivation(
(0): ConvBnReLU2d(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(1): Identity()
(2): Identity()
)