Hi iffi,
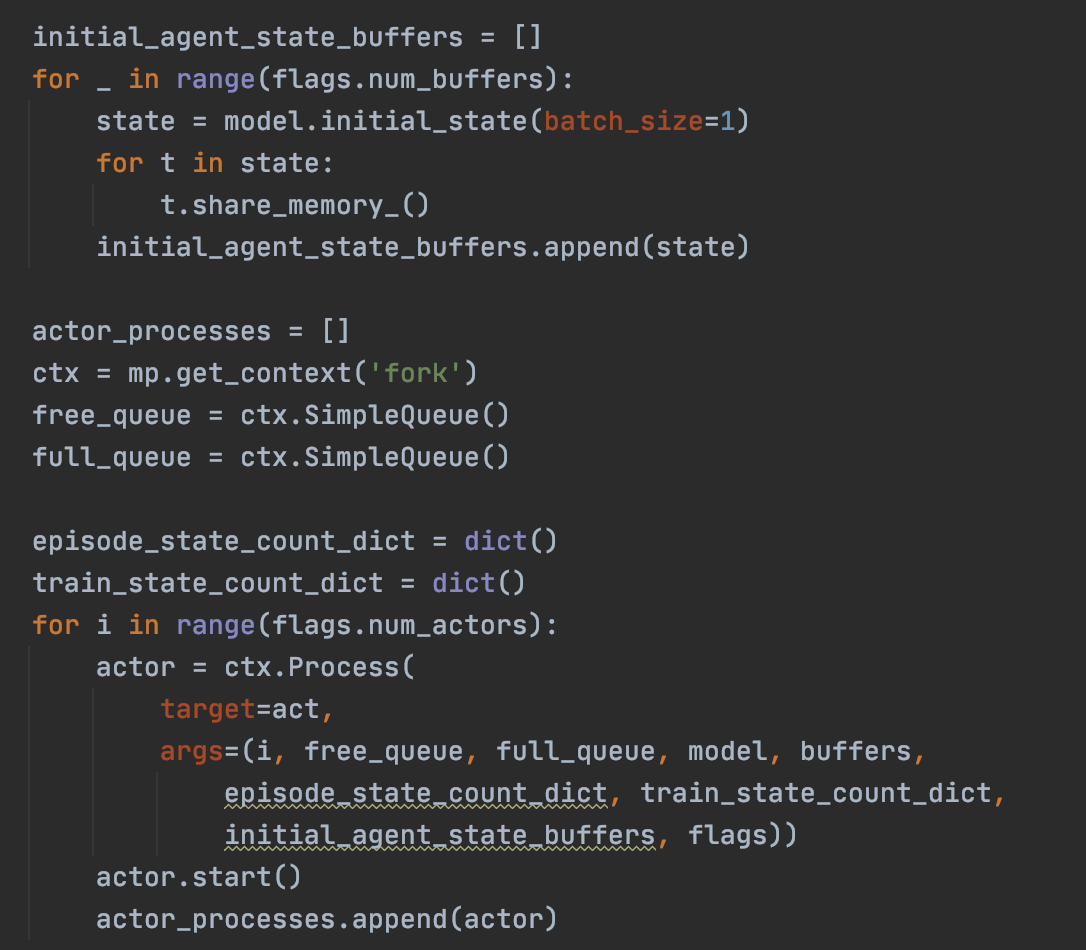
I think I’ve located the problem, but I don’t know how to fix it. As you know the IMPLALA model has actors and learners. I’m using the torchbeast implementation called monobeast: that run actors on a number of processes on CPU, and do the learning part on GPU. There are some drawbacks of this pattern, which also indicated in the torchbeast paper: the model require a large amount of shared memory between processes, and do the model eval and environment.step on cpu too. And their are some copies of tensors that is unnecessary. So as the frame number goes large, more and more memories were eaten by some unused tensors. That’s why no matter what buffer size and number of actors i use, the model always got an error when training for about 1.1M frames, there is no room for the actor model to do the forward operation.
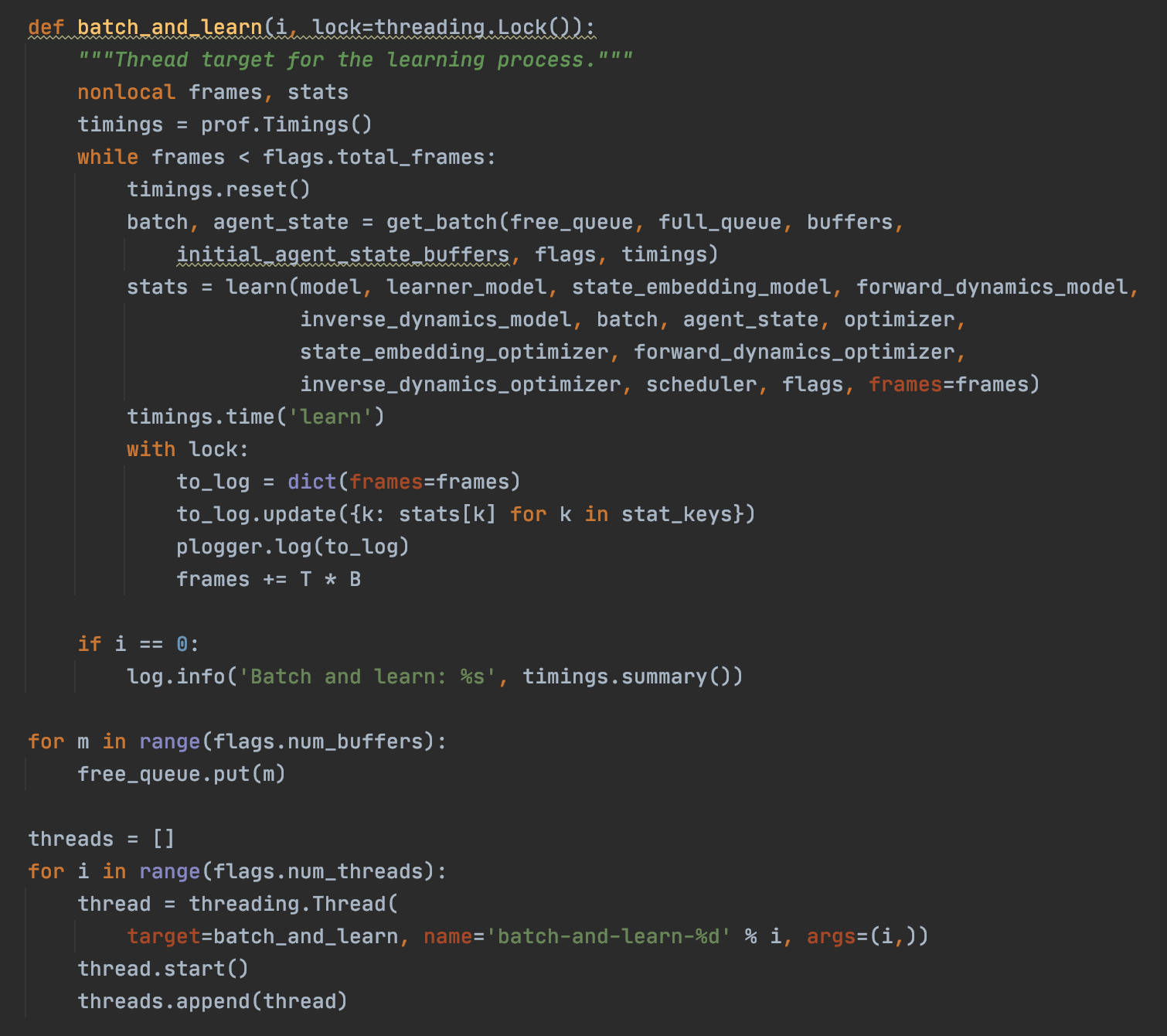
I wonder how I can free up those memory/ I’ve tried del output, and del loss. the limit increase to 1.3M frames but that’s it. here is the part of fill in the buffer, followed by the part of withdrawing the buffer.
`def act(i: int, free_queue: mp.SimpleQueue, full_queue: mp.SimpleQueue,
model: torch.nn.Module, buffers: Buffers,
episode_state_count_dict: dict, train_state_count_dict: dict,
initial_agent_state_buffers, flags):
try:
log.info('Actor %i started.', i)
timings = prof.Timings()
gym_env = create_env(flags)
if flags.num_input_frames > 1:
gym_env = FrameStack(gym_env, flags.num_input_frames)
if 'procgen' in flags.env:
env = ProcGenEnvironment(gym_env, flags.start_level, flags.num_levels, flags.distribution_mode)
else:
seed = i ^ int.from_bytes(os.urandom(4), byteorder='little')
gym_env.seed(seed)
env = Environment(gym_env, fix_seed=flags.fix_seed, env_seed=flags.env_seed)
env_output = env.initial()
agent_state = model.initial_state(batch_size=1)
agent_output, unused_state = model(env_output, agent_state)
while True:
index = free_queue.get()
if index is None:
break
# Write old rollout end.
for key in env_output:
buffers[key][index][0, ...] = env_output[key]
for key in agent_output:
buffers[key][index][0, ...] = agent_output[key]
for i, tensor in enumerate(agent_state):
initial_agent_state_buffers[index][i][...] = tensor
# Update the episodic state counts
episode_state_key = tuple(env_output['frame'].view(-1).tolist())
if episode_state_key in episode_state_count_dict:
episode_state_count_dict[episode_state_key] += 1
else:
episode_state_count_dict.update({episode_state_key: 1})
buffers['episode_state_count'][index][0, ...] = \
torch.tensor(1 / np.sqrt(episode_state_count_dict.get(episode_state_key)))
# Reset the episode state counts when the episode is over
if env_output['done'][0][0]:
for episode_state_key in episode_state_count_dict:
episode_state_count_dict = dict()
# Update the training state counts
train_state_key = tuple(env_output['frame'].view(-1).tolist())
if train_state_key in train_state_count_dict:
train_state_count_dict[train_state_key] += 1
else:
train_state_count_dict.update({train_state_key: 1})
buffers['train_state_count'][index][0, ...] = \
torch.tensor(1 / np.sqrt(train_state_count_dict.get(train_state_key)))
# delete output
del agent_output
# Do new rollout
for t in range(flags.unroll_length):
timings.reset()
with torch.no_grad():
agent_output, agent_state = model(env_output, agent_state)
timings.time('model')
env_output = env.step(agent_output['action'])
timings.time('step')
for key in env_output:
buffers[key][index][t + 1, ...] = env_output[key]
for key in agent_output:
buffers[key][index][t + 1, ...] = agent_output[key]
# Update the episodic state counts
episode_state_key = tuple(env_output['frame'].view(-1).tolist())
if episode_state_key in episode_state_count_dict:
episode_state_count_dict[episode_state_key] += 1
else:
episode_state_count_dict.update({episode_state_key: 1})
buffers['episode_state_count'][index][t + 1, ...] = \
torch.tensor(1 / np.sqrt(episode_state_count_dict.get(episode_state_key)))
# Reset the episode state counts when the episode is over
if env_output['done'][0][0]:
episode_state_count_dict = dict()
# Update the training state counts
train_state_key = tuple(env_output['frame'].view(-1).tolist())
if train_state_key in train_state_count_dict:
train_state_count_dict[train_state_key] += 1
else:
train_state_count_dict.update({train_state_key: 1})
buffers['train_state_count'][index][t + 1, ...] = \
torch.tensor(1 / np.sqrt(train_state_count_dict.get(train_state_key)))
timings.time('write')
full_queue.put(index)
if i == 0:
log.info('Actor %i: %s', i, timings.summary())
except KeyboardInterrupt:
pass
except Exception as e:
logging.error('Exception in worker process %i', i)
traceback.print_exc()
print()
raise e`
def get_batch(free_queue: mp.SimpleQueue,
full_queue: mp.SimpleQueue,
buffers: Buffers,
initial_agent_state_buffers,
flags,
timings,
lock=threading.Lock()):
with lock:
timings.time('lock')
indices = [full_queue.get() for _ in range(flags.batch_size)]
timings.time('dequeue')
batch = {
key: torch.stack([buffers[key][m] for m in indices], dim=1)
for key in buffers
}
initial_agent_state = (
torch.cat(ts, dim=1)
for ts in zip(*[initial_agent_state_buffers[m] for m in indices])
)
timings.time('batch')
for m in indices:
free_queue.put(m)
timings.time('enqueue')
batch = {
k: t.to(device=flags.device, non_blocking=True)
for k, t in batch.items()
}
initial_agent_state = tuple(t.to(device=flags.device, non_blocking=True)
for t in initial_agent_state)
timings.time('device')
return batch, initial_agent_state
Is there a way I can free those used buffer? Cause to my understanding, memory usage consistently increasing does not make sense right?
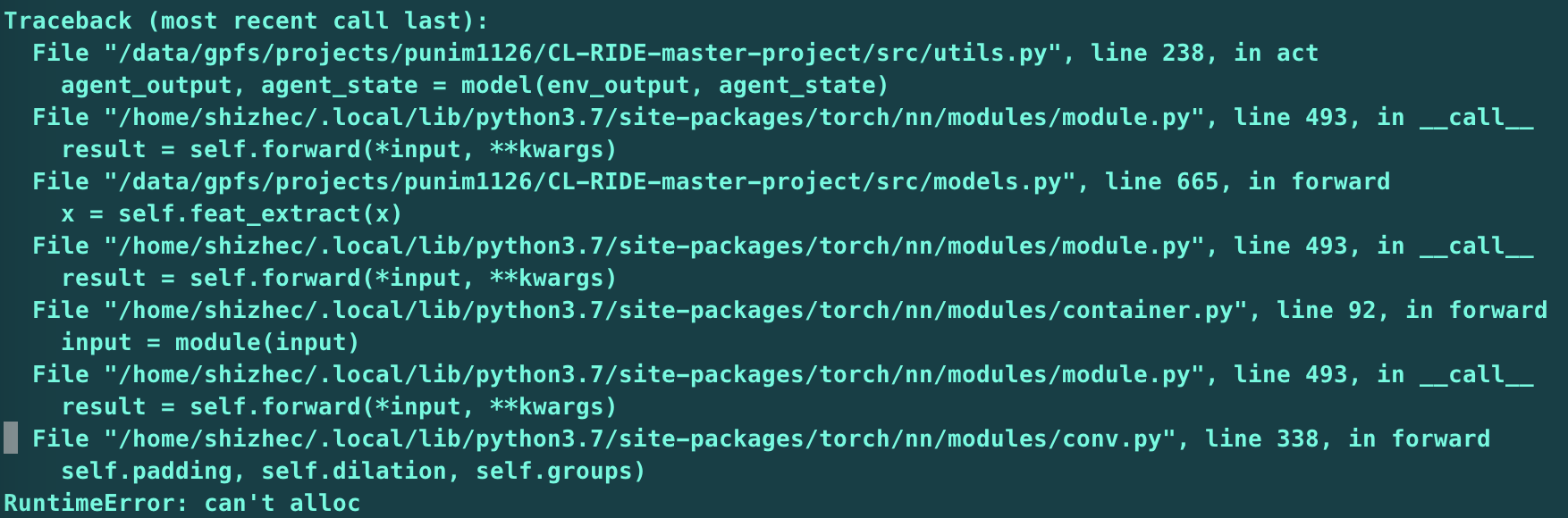
 . Can you give me some hints to to determine the problem root? I currently have 40 actors to run and fill the experience buffer
. Can you give me some hints to to determine the problem root? I currently have 40 actors to run and fill the experience buffer