Hello everyone,
I have a question regarding the Conv1d in torch,
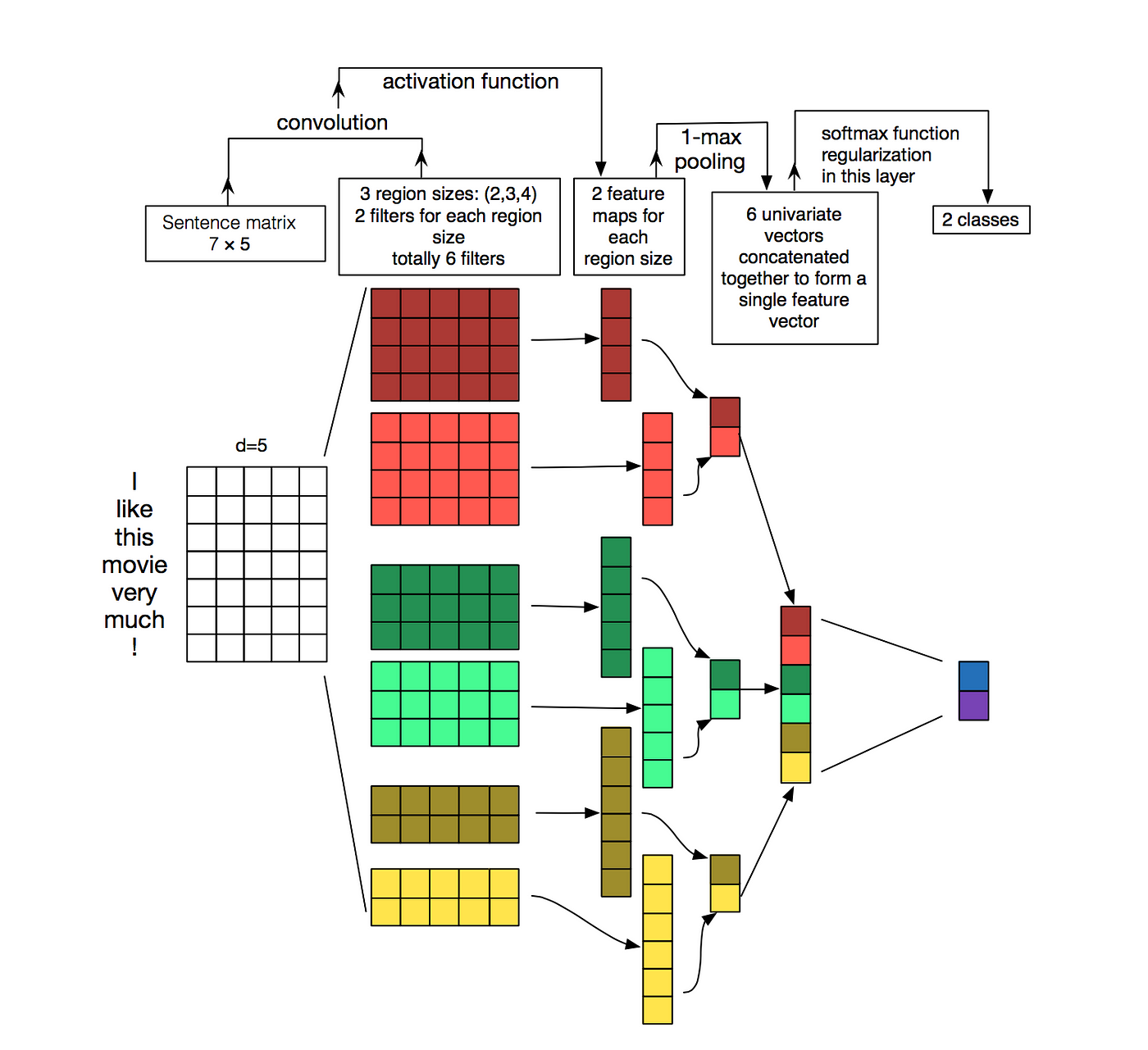
the simple model below, which works with text classification, has a ModuleList containing three Conv1d layers (each one dedicated to a specific filter size)
import torch
import torch.nn as nn
class TextClassifier(nn.Module):
def init(self, vocab_size, embedding_dim, num_classes):
super(TextClassifier, self).init()
my question is: it is necessary to use ModuleList and have Conv1d layer for each filter size, I mean is it work to have just one Conv1d layer that has the different filter sizes (2,3,4)
A ModuleList is just one way of organizing layers and is especially useful if you plan to use a for loop. What you do with those layers will be determined in the forward pass. (i.e. make them sequential or have them parallel process the same inputs).
Suppose you wanted 100x Conv1d layers with kernel sizes of 1 to 100, each taking the same embedded text input. You could do:
self.kernels = nn.ModuleList([])
for i in range(100):
self.kernels.append(nn.Sequential(
nn.Conv1d(embedding_dim, 100, kernel_size = i + 1),
nn.BatchNorm1d(100),
nn.ReLU()
)
)
...
#in the forward pass, with x as input
contexts = []
for i in range(100):
y = self.kernels[i](x)
contexts.append(y)
...
An individual Conv1d layer can only have one kernel_size.