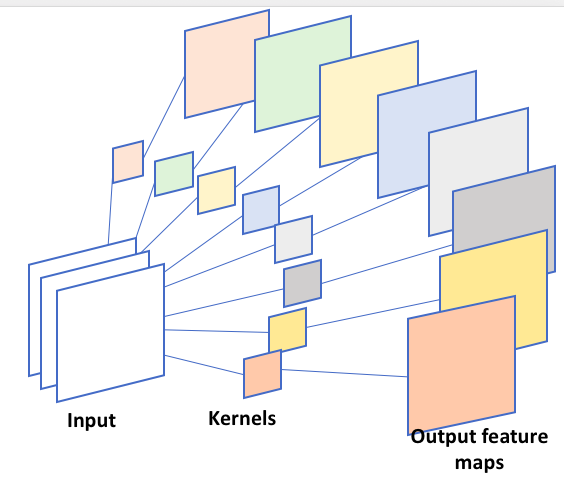
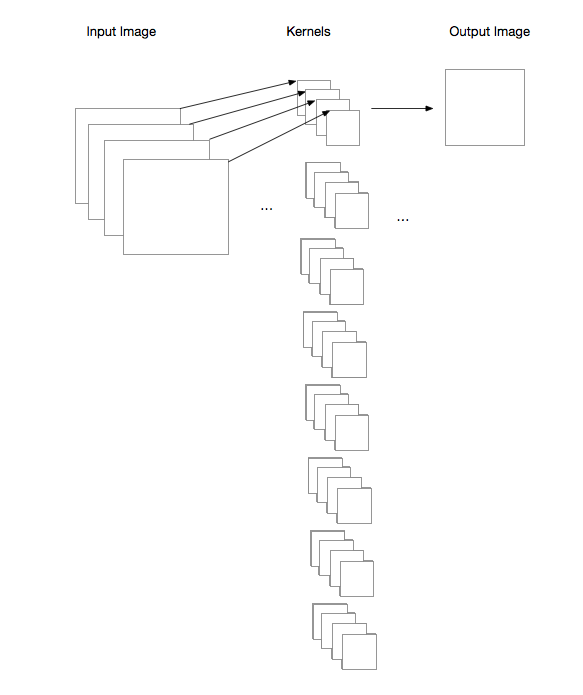
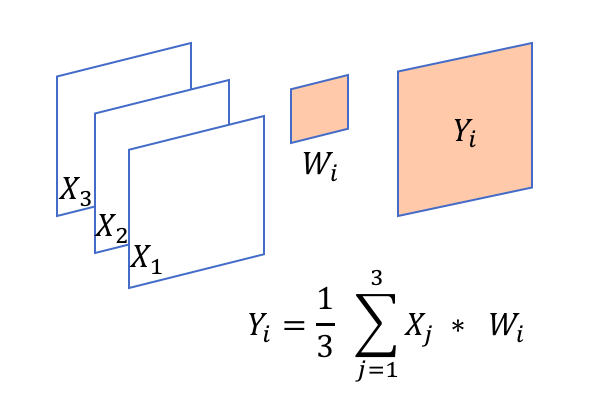
I am playing with the groups option in torch.nn.Conv2d(..). It appears that both in_channels and out_channels must be divisible by groups. But in theory, it is not necessary, for example, if I have in_channels=3, and groups=3, then out_channels=8 should give me the operation shown in the figure, but this will raise an error, saying “out_cnhannels is not divisable by groups”.
This works for in_channels=3, out_channels=9, and groups=3:
>>> conv = torch.nn.Conv2d(in_channels=3, out_channels=9,
kernel_size=(3,3), stride=1,
padding=0, dilation=1,
groups=3, bias=True)
>>> print(conv.weight.data.size())
torch.Size([9, 1, 3, 3])
So, I think out_channels=8 should work as well. Isn’t that right? ![]()