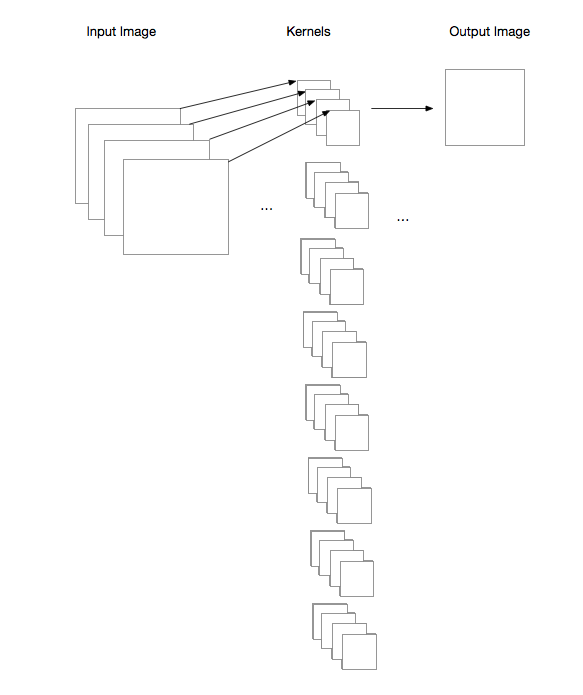
From what I understand, the number of channels in one kernel tensor is equal to the number of channels in the input image. E.g., if you set
c = torch.nn.Conv2d(in_channels=4, out_channels=8, kernel_size=(3, 3), groups=1)
you will have 8 kernel tensors with 4 channels each, corresponding to the following scenario:
Then, if you change it to
c = torch.nn.Conv2d(in_channels=4, out_channels=8, kernel_size=(3, 3), groups=2)
the 8 kernel tensors will be divided such that 2 of them are used for the first 2 image channels, and 2 of them are used for the other 2 image channels. The results are stacked, so if each kernel tensor has 4 channels, you have 2*4=8 output channels and 2 of them will be used for the other 2 image channels.

Now, if you change it to sth like this
c = torch.nn.Conv2d(3, 9, (3, 3), groups=3)
you would end up with 1 kernel channel per image channel:

Finally, if you write sth like you suggested:
c = torch.nn.Conv2d(in_channels=3, out_channels=8, kernel_size=(3, 3), groups=3)
the code will complain, because it wouldn’t now how to evenly distribute the 8 kernels among the 3 input image channels. Eg., the first channel might get 3 kernels, the 2nd gets 3, and the third gets 2? That’s possible but ambiguous.