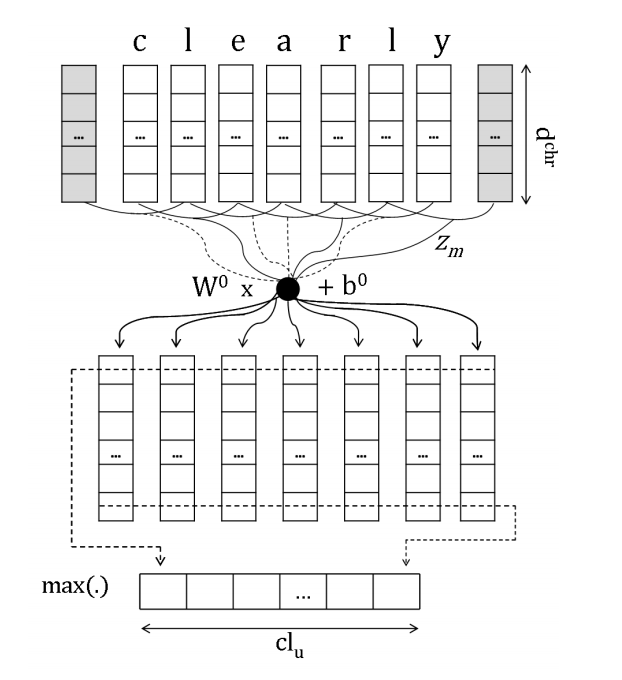
I am trying to implement conv+max_pooling for encoding sentence (as the above figure indicates), yet the documentation for conv2d is kind of messy. Does anyone have experience about this?
Basically, the input is a tensor a with dimension (sent_len, EMB_SIZE):
a = self.lookup(x_sent).unsqueeze(1) // I am using batch_size = 1
The output should be a tensor with dimension (1, EMB_SIZE) ?
the output of CNN should be size of (batch_size, EMB_SIZE, seq_len),
then you may use transpose() to transpose it to (seq_len, batch_size, EMB_SIZE), after which you are ready for the input of LSTM.