I was trying to quantize FBNet model in PyTorch.
Quantized version has several times bigger latency than fp32.
but on raspberry pi it gives some gain in latency but still slow.
here is the result of small benchmark (just one Conv+Bn+ReLU)
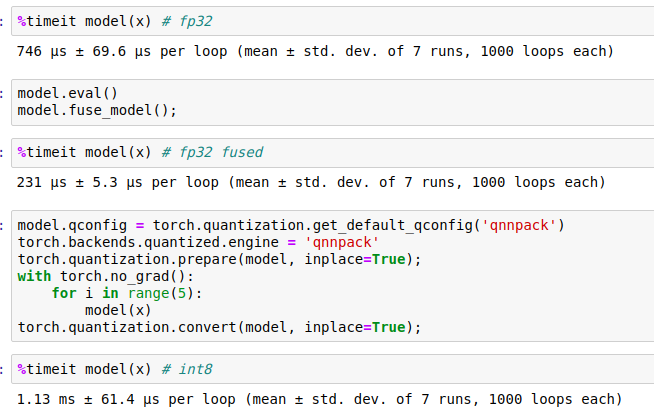
Is this an expected behavior ?
import torch
import torch.nn as nn
import torch.nn.quantized as nnq
from torch.quantization import QuantStub, DeQuantStub
class ConvBNRelu(nn.Module):
def __init__(self, cfg):
super(ConvBNRelu, self).__init__()
self.conv = nn.Conv2d(in_channels=cfg['in_channels'],
out_channels=cfg['out_channels'],
kernel_size=cfg['kernel_size'],
stride=cfg['stride'],
padding=cfg['padding'])
self.bn = nn.BatchNorm2d(num_features=cfg['out_channels'])
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class Backbone(nn.Module):
def __init__(self):
super(Backbone, self).__init__()
cfg = {
'stem' : {
'in_channels' : 3,
'out_channels' : 32,
'kernel_size' : (3, 3),
'stride' : (2, 2),
'padding' : (1, 1),
}
}
self.stem = ConvBNRelu(cfg['stem'])
self.quant = QuantStub()
self.dequant = DeQuantStub()
def forward(self, x):
x = self.quant(x)
x = self.stem(x)
x = self.dequant(x)
return x
def fuse_model(self):
torch.quantization.fuse_modules(self.stem, ['conv', 'bn', 'relu'], inplace=True)
model = Backbone()
torch.manual_seed(123)
x = torch.randn([1, 3, 34, 320], dtype=torch.float)*10
print(model)
%timeit model(x)
model.qconfig = torch.quantization.get_default_qconfig('qnnpack')
torch.backends.quantized.engine = 'qnnpack'
torch.quantization.prepare(model, inplace=True);
with torch.no_grad():
for i in range(5):
model(x)
torch.quantization.convert(model, inplace=True);
print(model)
%timeit model(x)