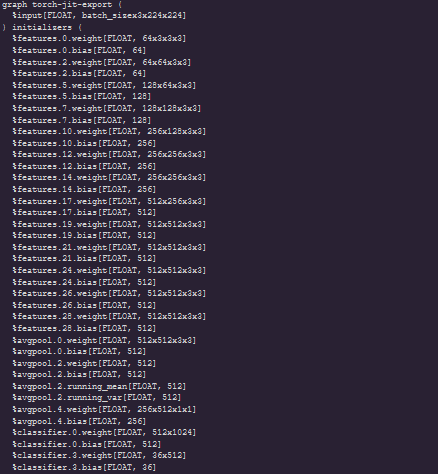
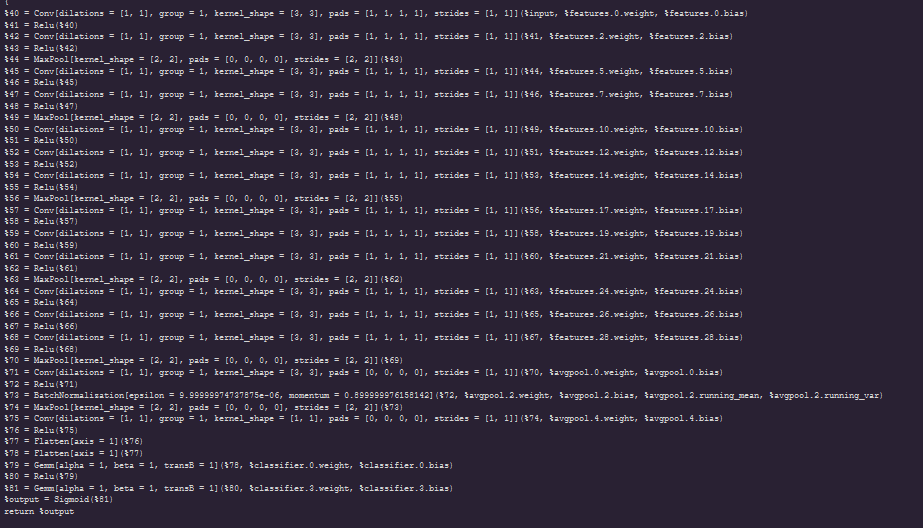
I have tested with torch.ones(1,3,224,224){input} and the model works but with my own inputs and same preprocessing used in training the onnx model produces different outputs from the torch model.
Code to convert the model to onnx format
import onnx
from onnx_tf.backend import prepare
model = model
model.load_state_dict(torch.load(PATH, map_location=torch.device('cpu')))
print("Model is loaded")
model.eval()
#Export model to ONNX format
x = torch.randn(1, 3, 224, 224).to(device)
torch.onnx.export(model,
x,
"vgg16.onnx",
opset_version=10,
do_constant_folding=True,
export_params=True,
input_names = ["input"],
output_names =["output"],
verbose=True,
dynamic_axes={'input' : {0 : 'batch_size'}, # variable length axes
'output' : {0 : 'batch_size'}}
)
Code for inference in onnx:
ort_session = ort.InferenceSession("/content/vgg16.onnx")
x = test_dataset.load_img(1).transpose(2,0,1)
plt.imshow(test_dataset.load_img(1))
def to_numpy(tensor):
if tensor.requires_grad:
return tensor.detach().cpu().numpy()
return tensor.cpu().numpy()
outputs = ort_session.run(
None,
{"input": x[None].astype("float32")},
)
# compare ONNX Runtime and PyTorch results
np.testing.assert_allclose(torch_out.detach().cpu(),
outputs[0],
rtol=1e-03,
atol=1e-05)
print("Exported model has been tested with ONNXRuntime, and the result looks good!")
AssertionError:
Not equal to tolerance rtol=0.001, atol=1e-05
Mismatched elements: 36 / 36 (100%)
Max absolute difference: 0.17844993
Max relative difference: 0.8394638
x: array([[0.171307, 0.180779, 0.179579, 0.225714, 0.232095, 0.220075,
0.443109, 0.470671, 0.488748, 0.538834, 0.530197, 0.539141,
0.038368, 0.028497, 0.096283, 0.401647, 0.279558, 0.50373 ,…
y: array([[0.338318, 0.345975, 0.340239, 0.349426, 0.356006, 0.352419,
0.478905, 0.489058, 0.498031, 0.514408, 0.505635, 0.498025,
0.199641, 0.17751 , 0.274733, 0.458645, 0.396497, 0.490221,…