I am trying to follow the guide from a scientific paper but can not work out how to convert the model from keras to VGG16
The paper is found at http://cs230.stanford.edu/projects_spring_2019/reports/18681590.pdf. The model is describe at the end of page 2 and start of 3.
I am taking the pretrainined VGG16 as the parameter and creating an output with 196 classes
class NetworkV1_4(nn.Module):#http://cs230.stanford.edu/projects_spring_2019/reports/18681590.pdf
def __init__(self, base, num_classes):
super().__init__()
self.base = base
self.base.classifier = nn.Sequential(
nn.Linear(in_features=25088, out_features=25088,bias=True),
nn.ReLU(inplace=True),
nn.Linear(in_features=25088, out_features=512,bias=True),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(512, num_classes),
)
def forward(self, x):
fc = self.base(x)
return fc
HI, I am trying to replicate the result seen in the paper. They are doing fine-grain vehicle recognition. They find that they need to add modifications to the architecture of VGG16 to get better result and remove overfitting. There is a link to a github which follows the architecture but I don’t know who to convert it to pytorch from keras (https://github.com/Xiaotian-WANG/Fine-Tune-VGG-Networks-Based-on-Stanford-Cars/blob/master/fine_tune_model.py)
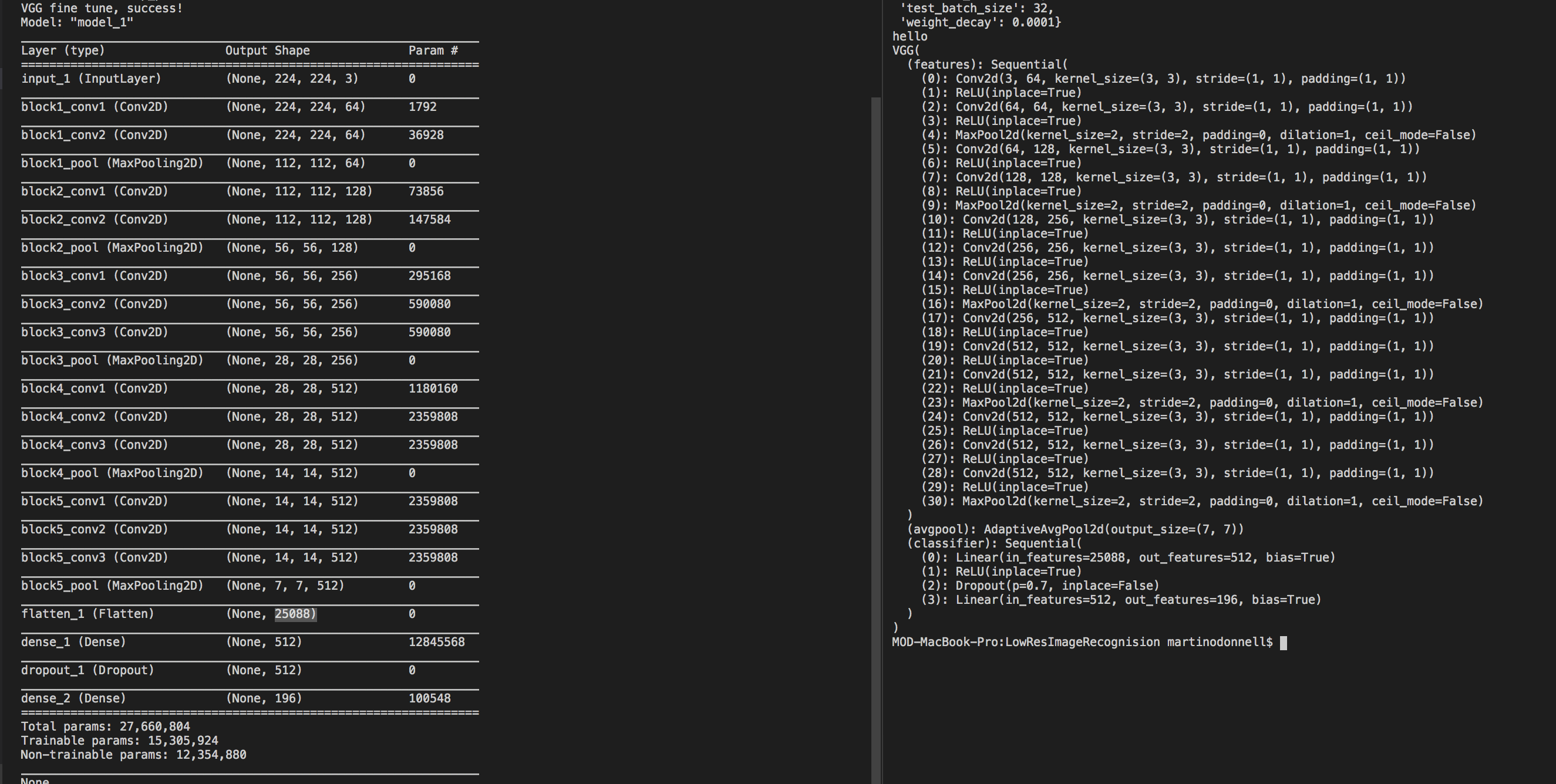
The left side is their model and the right is mine.
I am using the code seen below
class NetworkV1_5(nn.Module):#http://cs230.stanford.edu/projects_spring_2019/reports/18681590.pdf Take 2
def __init__(self, base, num_classes):#Define the layers
super().__init__()
self.base = base
self.base.classifier = nn.Sequential(
nn.Linear(in_features=25088, out_features=512, bias=True),
nn.ReLU(inplace=True),
nn.Dropout(0.7),
nn.Linear(512, num_classes),
)
def forward(self, x):
fc = self.base(x)
return fc
The paper I quoted above says that the first fully connected layer is dropped from VGG16. Then the second layers dimensions are decreased to 512. A dropout later is then added and then the last layer with 196 outputs(Number of fine-grain annotations int he dataset)
Why are you using nn.AdaptiveAvgPool2d to get to spatial dims of 7x7?
I see the Keras model using maxpooling to bring 14x14 down to 7x7.
Apart from that, the rest seems fine. It’s better to start training your model and see how well it is performing on the benchmarking dataset. On a side note, it is still better to have a network architecture that deviates from the one mentioned in the paper. You may get better results, you never know