I have converted a tensorflow code for timeseries analysis to pytorch and performance difference is very high, in fact pytorch layers cannot account for seasonality at all. It feels like I must be missing something important.
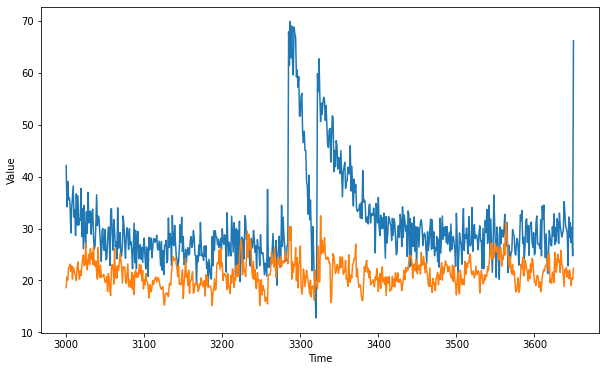
Please help find where the pytorch code is lacking that the learning is not up to the par. I noticed that loss values has high jumps when it encounters the season change and is not learning that. With the same layers, nodes and every other thing, I imagined the performance to be close.
# tensorflow code
window_size = 20
batch_size = 32
shuffle_buffer_size = 1000
def windowed_dataset(series, window_size, batch_size, shuffle_buffer):
dataset = tf.data.Dataset.from_tensor_slices(series)
dataset = dataset.window(window_size + 1, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_size + 1))
dataset = dataset.shuffle(shuffle_buffer).map(lambda window: (window[:-1], window[-1]))
dataset = dataset.batch(batch_size).prefetch(1)
return dataset
dataset = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(100, input_shape=[window_size], activation="relu"),
tf.keras.layers.Dense(10, activation="relu"),
tf.keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer=tf.keras.optimizers.SGD(lr=1e-6, momentum=0.9))
model.fit(dataset,epochs=100,verbose=0)
forecast = []
for time in range(len(series) - window_size):
forecast.append(model.predict(series[time:time + window_size][np.newaxis]))
forecast = forecast[split_time-window_size:]
results = np.array(forecast)[:, 0, 0]
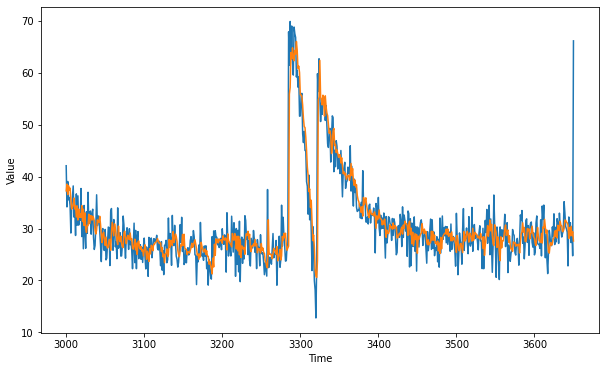
plt.figure(figsize=(10, 6))
plot_series(time_valid, x_valid)
plot_series(time_valid, results)
tf.keras.metrics.mean_absolute_error(x_valid, results).numpy()
# pytorch code
window_size = 20
batch_size = 32
shuffle_buffer_size = 1000
class tsdataset(Dataset):
def __init__(self, series, window_size):
self.series = series
self.window_size = window_size
self.dataset, self.labels = self.preprocess()
def preprocess(self):
series = self.series
final, labels = [], []
for i in range(len(series)-self.window_size):
final.append(np.array(series[i:i+window_size]))
labels.append(np.array(series[i+window_size]))
return torch.from_numpy(np.array(final)), torch.from_numpy(np.array(labels))
def __getitem__(self,index):
# print(self.dataset[index], self.labels[index], index)
return self.dataset[index], self.labels[index]
def __len__(self):
return len(self.dataset)
train_dataset = tsdataset(x_train, window_size)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
class tspredictor(nn.Module):
def __init__(self, window_size, out1, out2, out3):
super(tspredictor, self).__init__()
self.l1 = nn.Linear(window_size, out1)
self.l2 = nn.Linear(out1, out2)
self.l3 = nn.Linear(out2, out3)
def forward(self,seq):
l1 = F.relu(self.l1(seq))
l2 = F.relu(self.l2(l1))
l3 = self.l3(l2)
return l3
model = tspredictor(20, 100,10,1)
loss_function = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=1e-6, momentum=0.9)
for epoch in range(100):
for t,l in train_dataloader:
model.zero_grad()
tag_scores = model(t)
loss = loss_function(tag_scores, l)
loss.backward()
optimizer.step()
# print("Epoch is {}, loss is {}".format(epoch, loss.data))
forecast = []
for time in range(len(series) - window_size):
prediction = model(torch.from_numpy(series[time:time + window_size][np.newaxis]))
forecast.append(prediction)
forecast = forecast[split_time-window_size:]
results = np.array(forecast)
plt.figure(figsize=(10, 6))
plot_series(time_valid, x_valid)
plot_series(time_valid, results)
To generate data, you can use:
def plot_series(time, series, format="-", start=0, end=None):
plt.plot(time[start:end], series[start:end], format)
plt.xlabel("Time")
plt.ylabel("Value")
plt.grid(False)
def trend(time, slope=0):
return slope * time
def seasonal_pattern(season_time):
"""Just an arbitrary pattern, you can change it if you wish"""
return np.where(season_time < 0.1,
np.cos(season_time * 6 * np.pi),
2 / np.exp(9 * season_time))
def seasonality(time, period, amplitude=1, phase=0):
"""Repeats the same pattern at each period"""
season_time = ((time + phase) % period) / period
return amplitude * seasonal_pattern(season_time)
def noise(time, noise_level=1, seed=None):
rnd = np.random.RandomState(seed)
return rnd.randn(len(time)) * noise_level
time = np.arange(10 * 365 + 1, dtype="float32")
baseline = 10
series = trend(time, 0.1)
baseline = 10
amplitude = 40
slope = 0.005
noise_level = 3
# Create the series
series = baseline + trend(time, slope) + seasonality(time, period=365, amplitude=amplitude)
# Update with noise
series += noise(time, noise_level, seed=51)
split_time = 3000
time_train = time[:split_time]
x_train = series[:split_time]
time_valid = time[split_time:]
x_valid = series[split_time:]