Hi,
in convolution 2D layer, the input channel number and the output channel number can be different. What does the kernel do with various input and output channel numbers?
For example, if the input channel number is 32 and the output channel number is 1, how does the kernel converts 32 features into 1 feature? What is the kernel matrix like?
In the vanilla convolution each kernel convolves over the whole input volume.
Example: Your input volume has 3 channels (RGB image).
Now you would like to create a ConvLayer for this image. Each kernel in your ConvLayer will use all input channels of the input volume. Let’s assume you would like to use a 3 by 3 kernel. This kernel will have 27 weights and 1 bias, since (W * H * input_Channels = 3 * 3 * 3 = 27 weights).
The number of output channels is the number of different kernels used in your ConvLayer. If you would like to output 64 channels, your layer will have 64 different 3x3 kernels, each with 27 weights and 1 bias.
I hope this makes it a bit clearer.
Have a look at Stanford’s CS231n if your would like to dig a bit deeper.
Hi @liangstein!
I hope this image helps. Its from my lecture notes and shows how a feature map is produced from an image I with a kernel K. With each application of the kernel a dot product is calculated, which effectively is the sum of element-wise multiplications between I and K in an K-sized area within I.
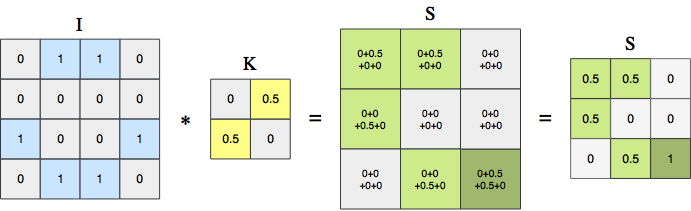
You could say that kernel looks for diagonal features. It then searches the image and finds a perfect matching feature in the lower left corner. Otherwise the kernel is able to identify only parts the feature its looking for. This why the product is called a feature map, as it tells how well a kernel was able to identify a feature in any location of the image it was applied to.
just a tiny nitpick.
lower right corner ?
“Each kernel in your ConvLayer will use all input channels of the input volume.”
I am confused with this line. So Convolution of an RGB image (with 3 channels) with a kernel will generate a Grey Scale Image (with 1 Channel) instead of an RGB image (with 3 channels)?
I was thinking Kernel would be applied to each channel as mentioned by @karmus89 and hence we would have 3 output channels for 3 input channels.
What am I missing?
Your first explanation is right.
Each kernel will produce one activation map.
If you would like to create 3 output channels, you could use 3 separate filters (all working on all input channels) or use grouped convolution (each filter working on a separate input channel).
Have a look at Stanford’s CS231n info on convolutions.
Thanks for explaining it in such a simple way!