According to my understanding, a convolution operation requires, for a kernel of size k, input batch of size B, input channels c, output channels f, image size n by n.
$$B * f * c * k^2 * n^2$$
The convolution can also be done on the fft domain by a element wise multiplication. Disregarding the cost of the FFT operations, for simplicity, we would have (note each complex multiplication requires 4 real ones)
$$
4 * B * f * c * n^2
$$
ps.: don’t know why formulas in markdown here are not working
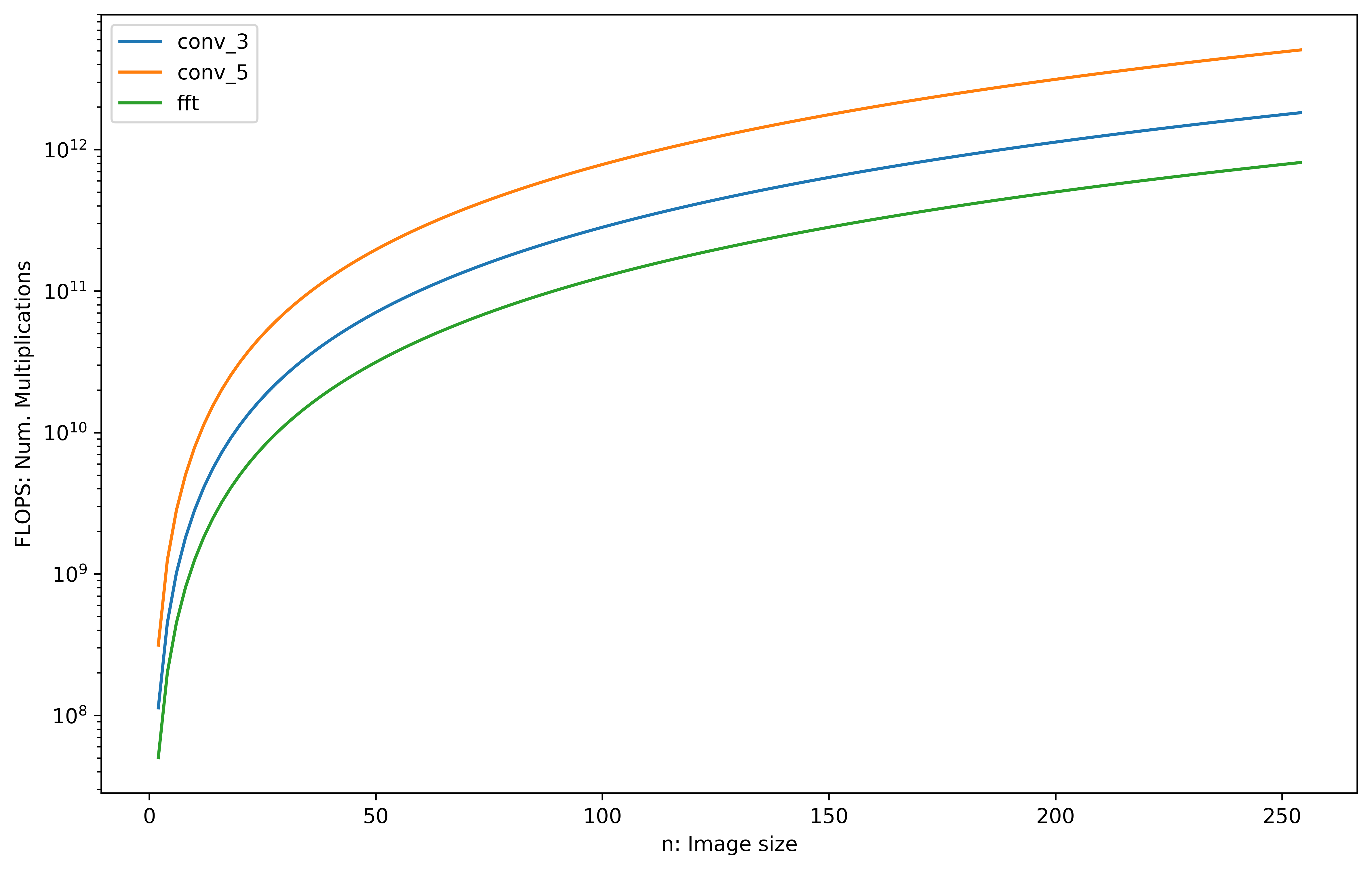
This plot show that using FFT should be faster, even when I add the cost for the FFT operations themselves.
At least part of your performance loss is you had to reimplement complex multiplication by hand using an unfused series of operations. Fusing the operations would be a big win. You should be able to use the PyTorch JIT’s fuser to test this.
I wrapped my functions calls inside a torch.nn.Module, and used jit
I know that my code is really messy, didn’t have still time to make it more readable neither better written. But, hopefully, is good enough to see that the timers are still in favor of the traditional Conv2d.
Conv2d
Conv2dFFT
Conv2dFFT (without JIT)
0.2027
0.8736
2.9177
I am using jit like this, not sure how to use fuser as you mentioned.