I haven’t written an autoencoder using your structure and assume you are wondering which setup to use in the transposed convolutions?
If so, you could start by “inverting” the encoder path and use the inverse channel dimensions. The kernel size, stride etc. should most likely be set in a way to reproduce the input spatial size.
If you don’t want to calculate it manually, add Print layers to the model to check the output activation shape and adapt the setup:
class Print(nn.Module):
def __init__(self):
super(Print, self).__init__()
def forward(self, x):
print(x.shape)
return x
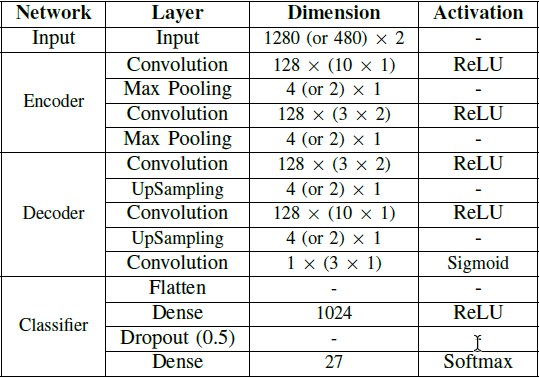
In the paper I’m reading, they show the following architecture
Do you think by upsampling they are saying that they’re actually using an upsampling function such as nn.Upsample or they are just using ConvTranspose2d and playing with the stride?
I mean, we can achieve the same downsampling without Max Pooling by playing with stride too right? But if they mention it on the architecture, it means they’re applying it right? What would you say given your experience?
I guess the best would be to contact the author to get more informations.
I would guess that UpSampling would refer to an nn.Upsample layer, but also a transposed conv could be used. However, I think the former might be more likely.
Do you see any mentions on the number of parameters? If the authors claim the UpSampling layers don’t use any trainable parameters, it should be an interpolation layer (i.e. nn.Upsample), on the other hand if these layers use parameters it would point towards a transposed conv.