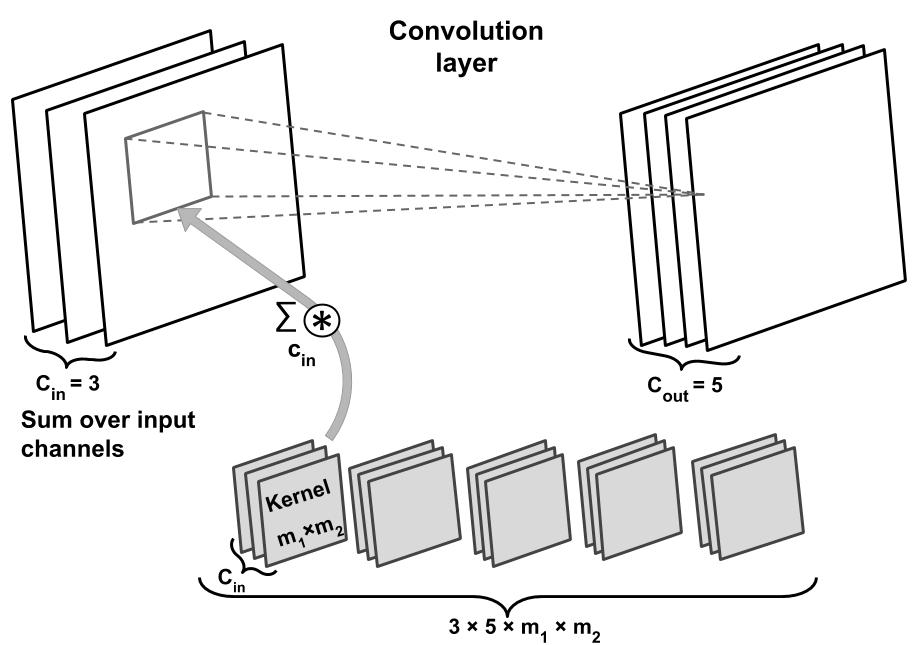
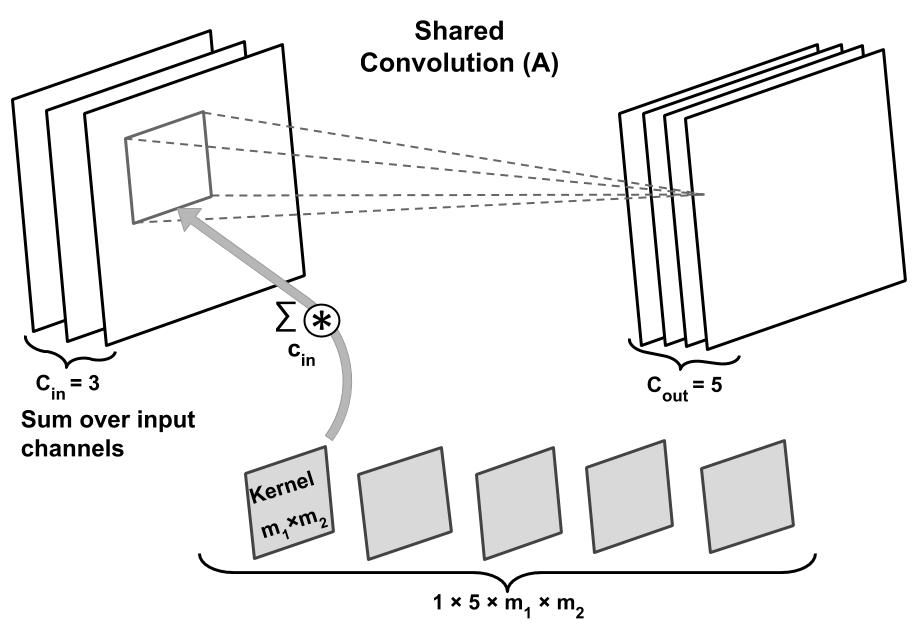
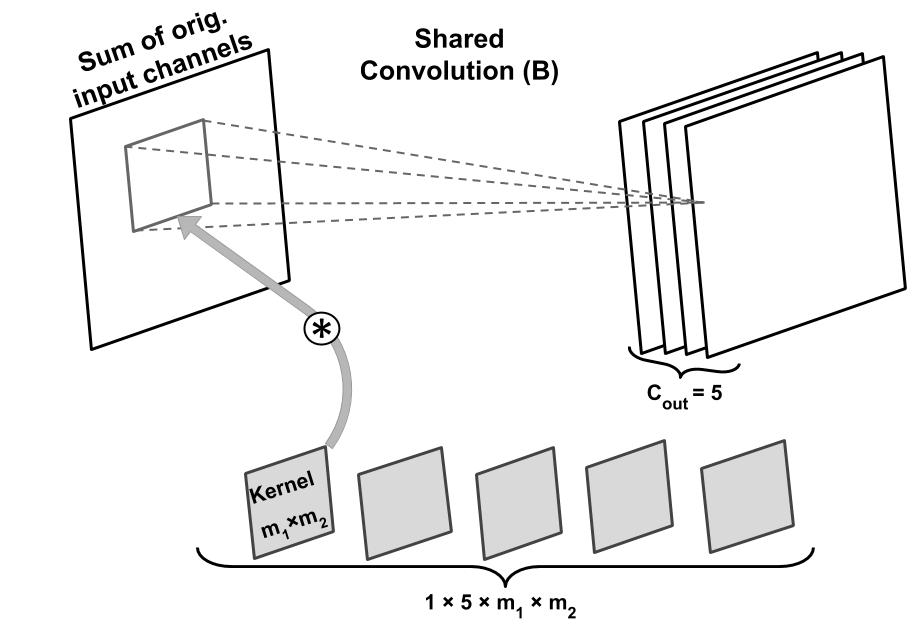
Hello,
What is the right way of implementing a convolutional layer that has shared weights for each input stream?
I have made an implementation where use convolutional layers with a single layer and then loop through each channel of the input stream to apply that convolution.
z = self.conv0(x[:,0,:].view(x.shape[0], 1, x.shape[2]))
for i in range(1, x.shape[1]):
z = torch.cat([z,self.conv0(x[:,i,:].view(x.shape[0], 1, x.shape[2]))], dim = 1)
Another idea that I have was shuffling weights of a convolutional layer but that wouldn’t save from the number of parameters used, although I would expect them to get similar to each other over training.
temp = model.conv1.conv.weight
temp = temp[:,torch.randperm(temp.shape[1]),:]
model.conv1.conv.weight = nn.Parameter(temp)
Finally, I thought the group parameter, which is used for depth-wise separable convolutions, can be used for that purpose, but that’s not the case in the documentation.
I am looking forward for your suggestions. Thank you in advance.