Hey everyone,
I am working on semantic segmentation and would like to extend an existing DeepLabV3+ (mobilenet backbone) with a recurrent unit (convolutional lstm).
My Idea was to concatinate the result of the segmentator at the current timestep T with its previous segmentation results (T-1 and T-2) and feed everything into the ConvLSTM (see picture).
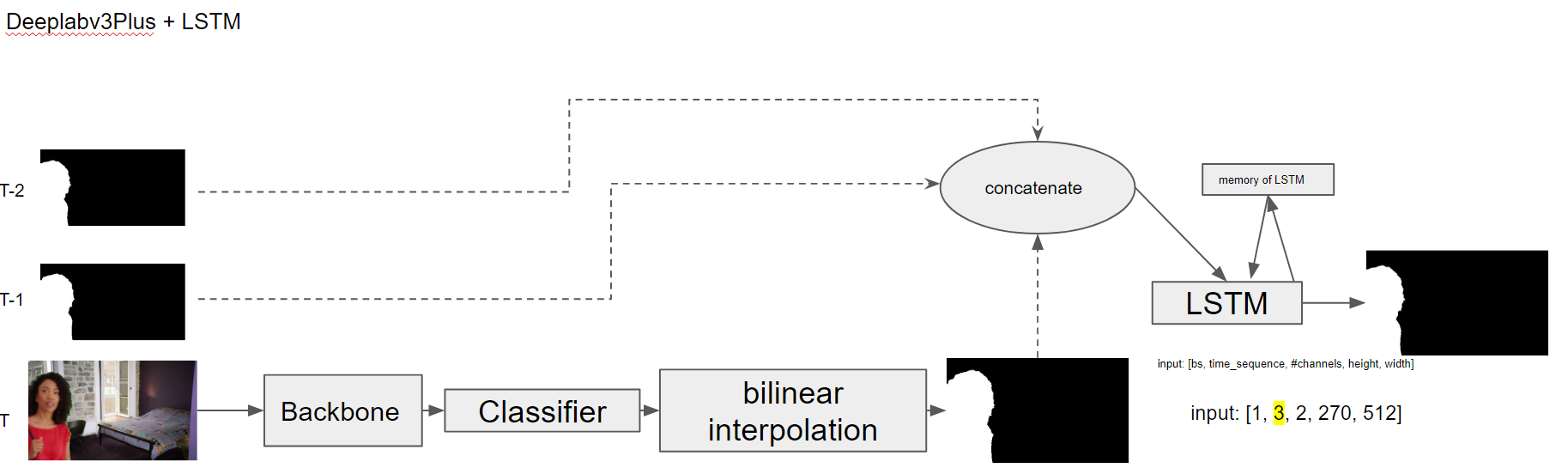
During training I always get this error:
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time
Setting retain_graph to true however causes that cuda runs out of memory.
I’ve tried following this thread
and it seems like the problem has to do with hidden_state.detach().
My network looks like this:
class Deep_mobile_lstmV2(nn.Module):
def __init__(self):
super().__init__()
self.base = deeplabv3plus_mobilenet(num_classes=2, pretrained_backbone=True)
self.lstm = ConvLSTM(input_dim=2, hidden_dim=[2], kernel_size=(3, 3), num_layers=1, batch_first=True,
bias=True,
return_all_layers=False)
self.hidden = None
def forward(self, x, *args):
# set old predictions
old_pred = args[0] # a list of the old prediction tensors
# get semantic segmentation by
out = self.base(x)
out = out.unsqueeze(1) #[bs,channels,H,W] --> [bs, timestep, channels, H,W]
# set old predictions to 0 if they dont exists (for the first 2 frames)
if len(args) != 0:
if None in old_pred:
for i in range(len(old_pred)):
old_pred[i] = torch.zeros_like(out)
# concatinate old predictions with current predictions [_,1,_,_,_] --> [_,3,_,_,_]
out = [out] + old_pred
out = torch.cat(out, dim =1)
out, self.hidden = self.lstm(out, self.hidden)
out = out[0][:,-1,:,:,:] # return only 1 segmentation
return out
(Please note that I left out some unimportant code that would have asserted, that the shapes match for concatination, so it is easier to read)
The Deeplab implementation is from this Git Repo and the ConvLSTM is from this repository (with line 142 in convlstm.py replaced by hidden_state=hidden_state)
My training loop looks like this:
for epoch in range(num_epochs):
old_pred = [None, None]
for batch in train_loader:
images, labels = batch
pred = net(images, old_pred)
loss = criterion(pred, labels.long())
optimizer.zero_grad()
# loss.backward(retain_graph=True) leads to memory issues
loss.backward() # throws error
optimizer.step()
old_pred[1] = old_pred[0]
old_pred[0] = pred.unsqueeze(1)
if I change
out, self.hidden = self.lstm(out, self.hidden) into
out, self.hidden = self.lstm(out) it is training but than the information in self.hidden would be lost with each new sample, right?
I am stuck at this problem for days and have no idea how to solve this. Any help would be appreciated!
