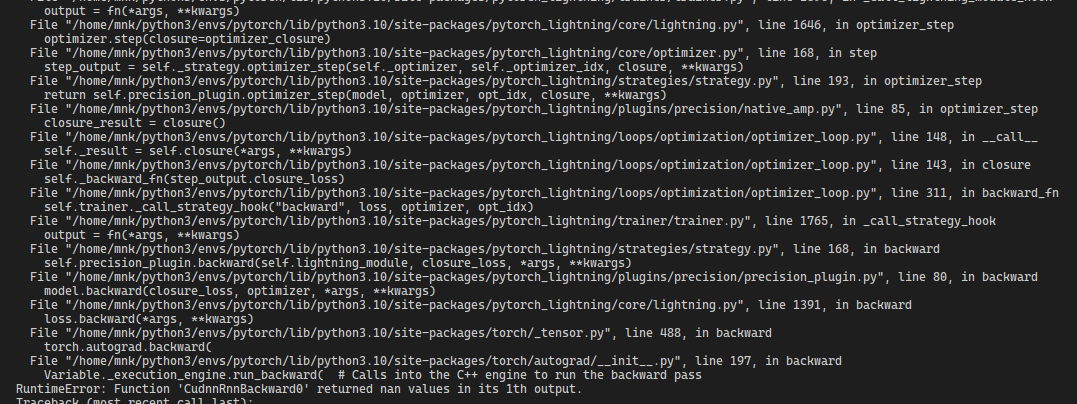
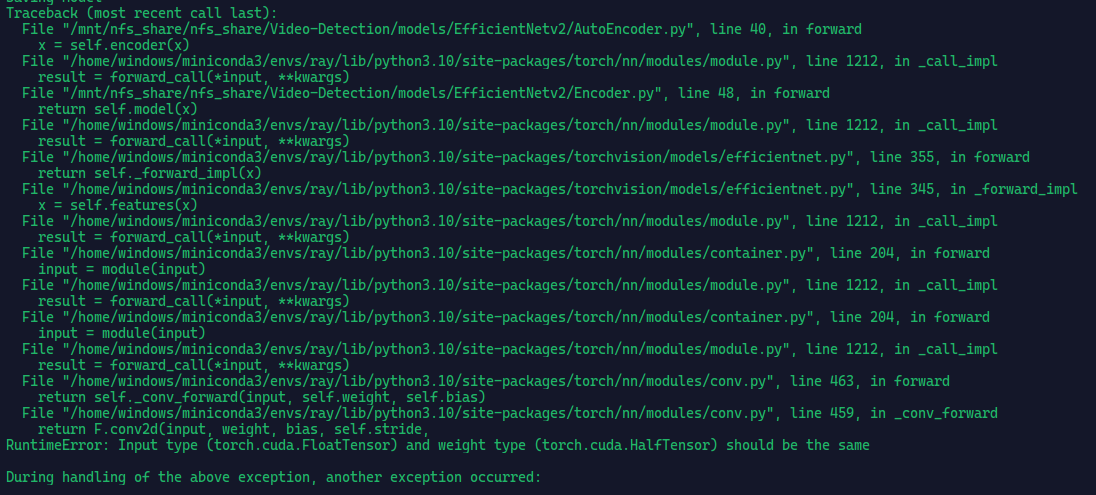
Logs :
I am getting this error everytime in random training steps ranging from 300-3000
Pytorch-lightning Parameters:
[AUTOENCODER_TRAIN]
max_epochs = 500
min_epochs = 250
#accelerator = gpu
benchmark = True
weights_summary = full
precision = 16
gradient_clip_val = 5
auto_lr_find = True
auto_scale_batch_size = True
auto_select_gpus = True
check_val_every_n_epoch = 1
fast_dev_run = False
enable_progress_bar = True
detect_anomaly=True
accumulate_grad_batches=8
track_grad_norm=2
sync_batchnorm = True
limit_val_batches=0.01
limit_train_batches=0.01
DataLoader Code
'@Author:NavinKumarMNK'
# Add the parent directory to the path
import sys
import os
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '../../')))
import utils.utils as utils
# Import the required modules
import torch
import torch.nn as nn
import torch.nn.functional as F
import pytorch_lightning as pl
from torch.utils.data import Dataset, DataLoader, random_split
import cv2
import PIL
import numpy as np
from utils.preprocessing import ImagePreProcessing
class AutoEncoderDataset(Dataset):
def __init__(self, batch_size:int, num_workers:int,
data_path, annotation_train) -> None:
super(AutoEncoderDataset, self).__init__()
self.data_path = data_path
self.annotation_train = open(annotation_train,
'r').read().splitlines()
self.batch_size = int(batch_size)
self.num_workers = int(num_workers)
self.preprocessing = ImagePreProcessing()
self.index = 0
def __len__(self):
return len(self.annotation_train)
def __getitem__(self, index:int):
i=0
while True:
i+=1
if index+i >= len(self.annotation_train):
index = 0
video_path = self.annotation_train[index+i]
video_path = os.path.join(self.data_path, video_path)
cap = cv2.VideoCapture(video_path.strip())
count: int = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print(count, i)
if not (cap.isOpened() and cap.get(cv2.CAP_PROP_FRAME_COUNT) > 0):
continue
if count < self.batch_size:
ret_frames = np.random.randint(0, count, count)
else:
ret_frames= np.random.randint(0, count, self.batch_size)
frames = []
original = []
# Get random frame indexes for batch size
for frame in ret_frames:
cap.set(1, frame)
ret, frame = cap.read()
if ret:
frame = np.transpose(frame, (2, 0, 1))
frame = self.preprocessing.transforms(torch.from_numpy(frame))
frame = self.preprocessing.preprocess(frame)
frame = self.preprocessing.augumentation(frame)
framex = self.preprocessing.improve(frame)
frames.append(framex)
framey = self.preprocessing.noise(frame)
original.append(framey)
X = torch.stack(frames, dim=0)
y = torch.stack(original, dim=0)
if(torch.isnan(X).any() or torch.isnan(y).any()):
print("reported")
continue
else:
break
return X, y
class AutoEncoderDataModule(pl.LightningDataModule):
def __init__(self, batch_size:int, num_workers:int,
data_path, annotation_train) -> None:
super(AutoEncoderDataModule, self).__init__()
self.annotation_train = annotation_train
self.batch_size = int(batch_size)
self.num_workers = int(num_workers)
self.data_path = data_path
def setup(self, stage=None):
full_dataset = AutoEncoderDataset(self.batch_size, self.num_workers,
self.data_path, self.annotation_train)
train_size = int(0.8 * len(full_dataset))
val_size = int(0.1 * len(full_dataset))
test_size = len(full_dataset) - train_size - val_size
self.train_dataset, self.val_dataset, self.test_dataset = random_split(
full_dataset, [train_size, val_size, test_size])
def train_dataloader(self):
return DataLoader(self.train_dataset, batch_size=1, num_workers=self.num_workers,
shuffle=True, drop_last=True, pin_memory=True)
def val_dataloader(self):
return DataLoader(self.train_dataset, batch_size=1, num_workers=self.num_workers,
shuffle=True, drop_last=True, pin_memory=True)
def test_dataloader(self):
return DataLoader(self.train_dataset, batch_size=1, num_workers=self.num_workers,
shuffle=True, drop_last=True, pin_memory=True)
if __name__ == '__main__':
dataset_params = utils.config_parse('AUTOENCODER_DATASET')
annotation_train = utils.dataset_image_autoencoder(
dataset_params['data_path'])
dataset = AutoEncoderDataModule(**dataset_params,
annotation_train=annotation_train)
dataset.setup()
train_loader = dataset.train_dataloader()
from models.EfficientNetb3.AutoEncoder import AutoEncoder
model = AutoEncoder().to('cuda:0').half()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
import time
for i, (x, y) in enumerate(train_loader):
x = x.view(x.size(1), x.size(2), x.size(3), x.size(4))
y = y.view(y.size(1), y.size(2), y.size(3), y.size(4))
out = model(x)
print(out.shape)
time.sleep(10)
#train the model
loss = F.mse_loss(out.to('cuda:0'), y.to('cuda:0'))
loss.backward()
#update the model
optimizer.step()
optimizer.zero_grad()