Hello,
In part of my model, a tensor that is not parameters gets modified during the forward() call and I want to remember it. As I use DataParallel, this tensor is registered as a buffer so that it will be saved from the first replica, as explained here in the second warning: DataParallel — PyTorch 2.1 documentation
The modification to this tensor needs to be in-place. Hence, I want to use copy_.
This is from there that I found a weird behavior for copy_, so I put the code below just as a sample displaying it (happening without DataParallel).
Here is my sample code:
import torch
import torch.nn as nn
import torch.optim as optim
from torchviz import make_dot
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.lin = nn.Linear(4, 8, bias=False)
self.lin_bis = nn.Linear(8, 4, bias=False)
self.register_buffer('tensor_bidon', torch.ones(self.lin.weight.shape))
def forward(self, x):
self.tensor_bidon.copy_(self.lin.weight)
x = self.lin(x)
x = self.lin_bis(x)
x = torch.matmul(x, self.tensor_bidon.t())
return x
mymod = MyModel()
loss_mine = torch.nn.MSELoss()
optimizer_mine = optim.Adam(mymod.parameters())
mymod.train()
for i in range(5):
print(f'-------- {i} ---------')
optimizer_mine.zero_grad()
inp = torch.randn(10, 4)
target = torch.randn(10, 8)
outputs_full = mymod(inp)
loss = loss_mine(outputs_full, target)
dot = make_dot(outputs_full, params={**{'inputs': inp}, **dict(mymod.named_parameters())})
dot.render(f"MYDIAG_SINGLE{i}", format='png')
print(mymod.lin.weight)
loss.backward()
optimizer_mine.step()
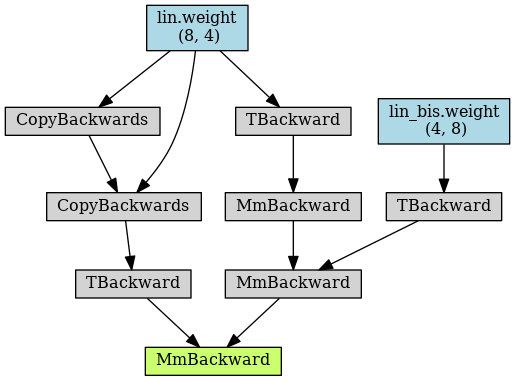
Here is the first autograd graph forward (as saved with make_dot in my code above):
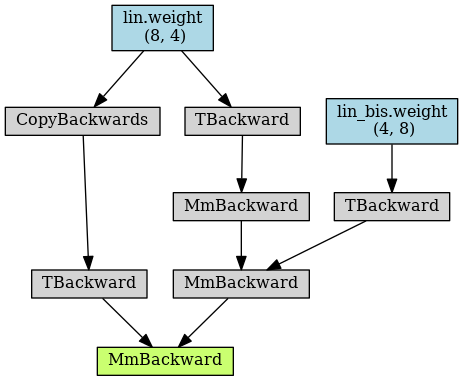
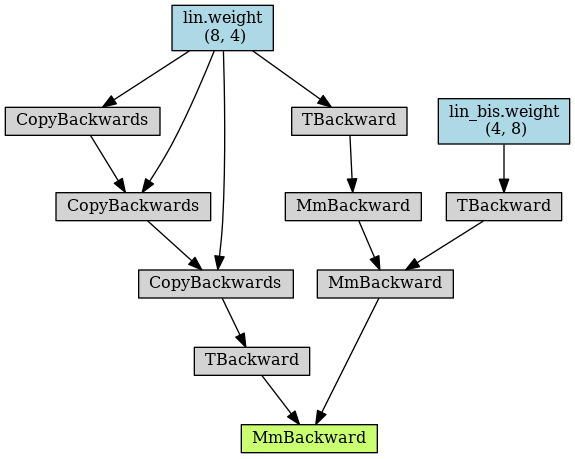
As you can see (in the posts below), the CopyBackwards operation gets duplicated in the following iterations.
Do you have any hint as to why this happens?
Many thanks!