jcowles
October 7, 2020, 5:43am
1
Hey all,
I’m finding that our native file buffer reader can load data about 300x faster if we can skip a numpy ndarray copy. Unfortunately, all attempts to go directly to PyTorch seem to be orders of magnitude slower than going through numpy.
Is there any way I can memcpy (from Python) my data directly into a Tensor efficiently?
Stats:
Tensor: 90 seconds
torch.tensor(buffer)
Tensor Set_ + FloatStorage: 48 seconds
tensor.set_(FloatStorage(buffer))
TorchVision loader: 7 seconds
Numpy conversion: 0.7 seconds
torch.from_numpy(numpy.asarray(buffer)) # uses numpy protocol
Native loader: 0.002 seconds
While the Numpy version is quite a nice improvement, you can see the motivation to get our raw data into tensors directly and also skip Numpy.
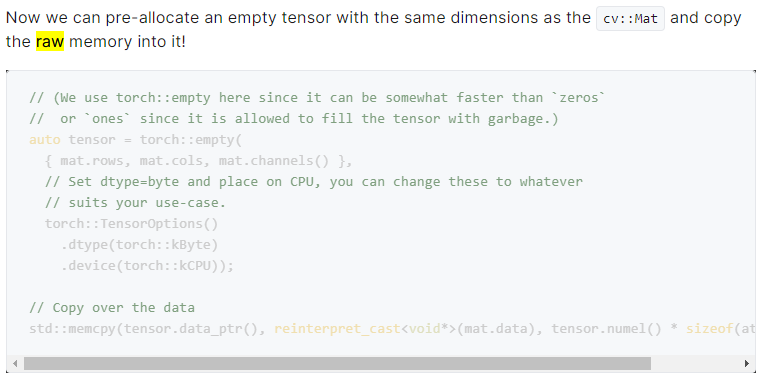
I’m looking for something like this C++ code, but in Python:
A similar request here:
opened 12:40PM - 12 Mar 20 UTC
module: docs
module: memory usage
triaged
enhancement
module: numpy
NumPy has utilities that allow to create an array from a ctypes pointer in pure … Python (without C++ extensions):
- https://docs.scipy.org/doc/numpy/reference/routines.ctypeslib.html#module-numpy.ctypeslib:
- https://numpy.org/doc/stable/reference/routines.ctypeslib.html#numpy.ctypeslib.as_array
- https://docs.scipy.org/doc/numpy/reference/generated/numpy.ndarray.ctypes.html
In C++ land, it seems that [`torch::from_blob`](https://pytorch.org/cppdocs/api/function_namespacetorch_1ad7fb2a7759ef8c9443b489ddde494787.html#function-documentation) should do the trick, but it has no binding to Python.
I propose to have utilities that would allow to do without passing by NumPy first or creating a C++ extension for a single-function `torch::from_blob` call, i.e. Python binding for `torch::from_blob` (that exist in java bindings btw), potentially with a custom deleter.
Context: I'd like to make a very thin ffmpeg audio-reading wrapper: the C code would do that allocation, return it to calling code, and the calling code would be responsible to free that memory. Pseudocode for NumPy (I still need to fix the C code) is here: https://github.com/vadimkantorov/audioprimer/blob/master/decode_audio.py . Ideally I'll have a single C file that's independent of NumPy/Torch and just slightly different versions of interfacing with it. I can think of some alternatives for this particular case, but Python way of creating a tensor from a raw ctypes pointer still may be useful for existing ctypes codebases.
Following that last post, this code is the fastest pure-Torch implementation I can muster, however I’m not sure if it’s leaking memory and it’s still slower than numpy:
from_buffer: 1.1 seconds
t = torch.Tensor()
s = torch.Storage.from_buffer(buffer, byte_order="native")
t.set_(s)
Thanks,