Hello,
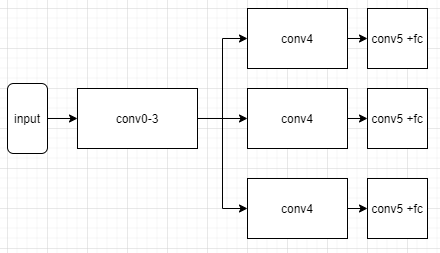
I have a multi branch architecture, with 3 branches at the end.
I would like to do a warm start of training, by loading a pre-trained state dictionary which only has 1 branch at the end.
So after loading the state dictionary, I would like to copy the weights of branch1 to branch2 and branch3.
This is what I have so far:
pretrained_dict = torch.load('H:/workspace/pretrain/epoch_500_pretrain_resnet50.pth')
model_dict = model.state_dict()
# 1. filter out unnecessary keys
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
# 2. overwrite entries in the existing state dict
model_dict.update(pretrained_dict)
# 3. load the new state dict
model.load_state_dict(model_dict)
# copy braches 0 -> branches 1/2
#model.branches[1].weight.data = model.branches[0]weight.data ??
The problem is the last line of code, i do not know how to address the models weight data.
I tried to look on forums, but i cant really find a correct way to do this.
Following your advice i tried to copy with .weight and .bias, but I fail to get results.
After the loading the state dict of a model that only has 1 branch (called branch 0), branch 0 achieves the same result as it should, if i disable the other branches during forward prop. So that branch is confirmed to have correct weights and biases.
But if i allow the images to also go through the branch 1 and branch 2 (which should have the same weights/biases), the performance goes down greatly, meaning I failed to copy the weights and biases, or there could be something else Im missing.
I used the following code to make sure i take into account every parameter:
for name, child in model.named_children():
for name2, params in child.named_parameters():
print(name, name2)
Then a wrote a pretty long manual copy code:
(please ignore incorrect comment names of resnet parts)
This sounds like using the .data attribute.
If i wish to train these other branches for similar but slightly different classification, would you suggest copying batch norm running stats?
Since you mentioned hidden side effects, im not sure if it is a good idea or not.
If you are copying the trainable parameters to side branches, I would recommend to copy everything (all parameters and buffers) to these branches. This might give you a “good initialization” for the training of these classifiers.
I’m not sure, if this approach is better train training from scratch, but I can see the similarity to using a pretrained model for a new classification task.
I did do the running_mean and running_var for bn layers, the result is closer if i propagate the same tensor through all branches but still incorrect.
Would it be easier to make 3 instances of the same model, load the state dictionary (which holds trained branch 0 ) and somehow merge the branch 0-s together and rename them 1/2? Altought not sure how could I do that either
Could you post your model architecture so that we could have a look?
The mentioned approach sounds simpler and if you would just like to load the same parameters and buffers, this dummy code shows how to do so using submodules:
Hey, sorry for the late reply.
Indeed I found a post of yours about model ensemble somewhere else, and decided to go with creating 3 instances of the same model, load all their state dictionaries in the usual way:
define 3 submodels
model0 = PABN()
model1 = PABN()
model2 = PABN()
# load state dict of 3 models
checkpoint = torch.load('epoch_500.pth')
model0.load_state_dict(checkpoint['model_state_dict'], strict=False)
model1.load_state_dict(checkpoint['model_state_dict'], strict=False)
model2.load_state_dict(checkpoint['model_state_dict'], strict=False)
# freeze backbones
freeze_backbones = True
if freeze_backbones:
with torch.no_grad():
# freeze parameters
for name, child in model0.named_children():
if name == 'backbone':
for name2, params in child.named_parameters():
params.requires_grad = False
for name, child in model1.named_children():
if name == 'backbone':
for name2, params in child.named_parameters():
params.requires_grad = False
for name, child in model2.named_children():
if name == 'backbone':
for name2, params in child.named_parameters():
params.requires_grad = False
# create a new model ensemble
model = EnsembleModels(model0, model1, model2)
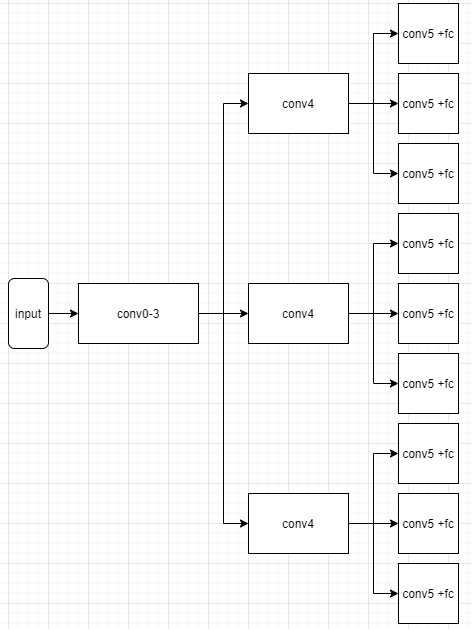
This ended up in just as it would be an actual branching tree network. There are 3 different backbones, but they are frozen, so they do not change and stay exactly the same. The downside is the higher memory usage I guess.
And here I have the problem again. And this time I would like it again if i could copy weights and biases in a reliable way, but i still dont know how to do it. When I used the previously mentioned methods (copy weigth data + bias data), i got a close but still not same performance, therefore i cannot trust it, and the training after that resulted in lower performance as I remember, compared to the case of loading with state dictionary and ensembling with frozen conv0-3.
Since I know that training the conv4+conv5 resulted in better perfomance, Im not sure about freezing conv4 as well, as I have the feeling that those higher level features do need some re-trainign in order to specialize for their data. So I cannot really use the same method, when i froze the conv0-3. I think freezing conv0-3 was okay because they have low level feratures that doesnt really need specialization too much.