I register an op in c++ with the reference of https://pytorch.org/tutorials/advanced/dispatcher.html#for-operators-that-do-not-need-autograd.I implement cuda device backend only and the autograd is also impl in c++. But I notice the autograd kernel needs to redispatch : it needs to call back into the dispatcher to get to the inference kernels, e.g. CPU or CUDA implementations.
I complie th c++ extension successfully. But when I import the new python module , coredump occures. I debug it with gdb and the stack information show as the following:
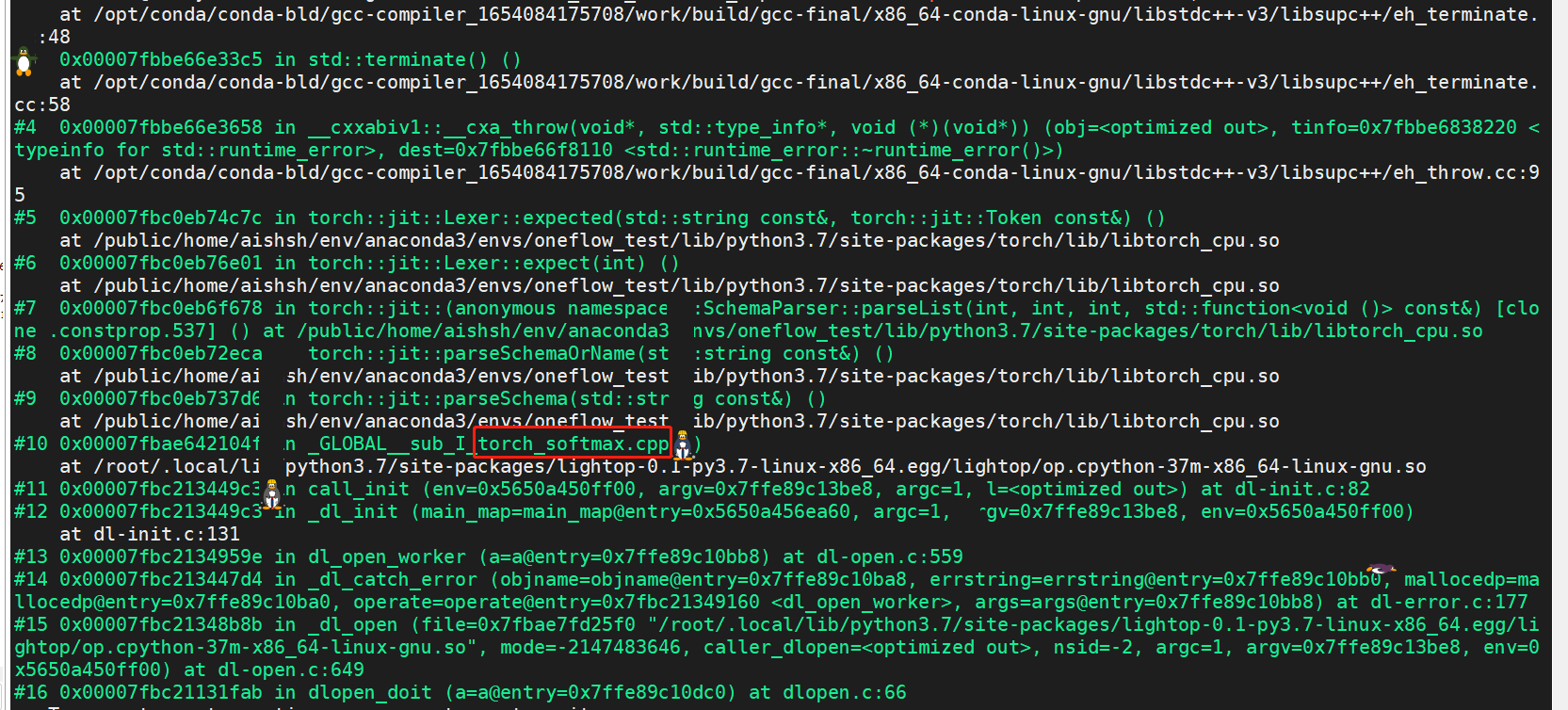
torch_softmax.cpp is the file defining the autograd kernel calling. part of its information just like this
#include "torch_softmax.h"
#include <ATen/core/dispatch/Dispatcher.h>
#include <torch/library.h>
#include <torch/types.h>
namespace at {
namespace native {
Tensor fuse_softmax_forward(const Tensor &input, const int64_t dim, const bool half_to_float) {
// C10_LOG_API_USAGE_ONCE("lightop.csrc.torch_softmax.fuse_softmax_forward");
static auto op = c10::Dispatcher::singleton()
.findSchemaOrThrow("myops::fuse_softmax_forward", "")
.typed<decltype(fuse_softmax_forward)>();
return op.call(input, dim, half_to_float);
}
namespace detail {
Tensor fuse_softmax_backward(const Tensor& grad, const Tensor& output, int64_t dim, const Tensor& input) {
static auto op =
c10::Dispatcher::singleton()
.findSchemaOrThrow("myops::fuse_softmax_backward", "")
.typed<decltype(fuse_softmax_backward)>();
return op.call(
grad,
output,
dim,
input);
}
} // namespace detail
TORCH_LIBRARY_FRAGMENT(myops, m) {
m.def("fuse_softmax_forward(const Tensor &input, const int64_t dim, const bool half_to_float) -> Tensor");
m.def("fuse_softmax_backward(const Tensor& grad, const Tensor& output, int64_t dim, const Tensor& input) -> Tensor");
}
} // namespace ops
} // namespace vision
I want to keep the autograd module with c++ implementation to improve performance. The stack info shows the op calls in jit method. I suspect this problem is related to the dynamic dispatch selection. But I don’t know how to call the definite cuda backend or how to debug it furthermore. Could someone give me some advice?