Well, I have investigated / worked more on this.
Here is a small working example with my mock data structure.
import numpy as np
b = (np.array([ 1.17, 1.65, 1.61, 7.61]), 0.0, np.array([1.]), 'file_vel_16_loc_A.wav', 206050, 'vel_16_loc_A')
c = (np.array([ 2.17, 2.65, 2.61, 2.61]), 0.0, np.array([1.]), 'file_vel_8_loc_D.wav', 206050, 'vel_8_loc_D')
batch = [b, c, b, c, b]
def collate_fn(batch):
*_, conditions = zip(*batch)
unique_conditions = list(set(conditions))
condition_batches = {c: [] for c in unique_conditions}
for b in batch:
condition_batches[b[5]].append(b)
batches = [list(zip(*condition_batches[c])) for c in unique_conditions]
for i in range(len(batches)):
for j in [0, 1, 2, 4]:
batches[i][j] = np.stack(batches[i][j], axis=0)
return batches
out = collate_fn(batch)
and my out looks like intended. It is a list of length 2, where each element is grouped by the condition.
So far so good.
[
# here comes condition one called vel_8_loc_D
[array([[2.17, 2.65, 2.61, 2.61],
[2.17, 2.65, 2.61, 2.61]]),
array([0., 0.]),
array([[1.], [1.]]),
('file_vel_8_loc_D.wav', 'file_vel_8_loc_D.wav'),
array([206050, 206050]),
('vel_8_loc_D', 'vel_8_loc_D')],
# and now the condition two vel_16_loc_A
[array([[1.17, 1.65, 1.61, 7.61],
[1.17, 1.65, 1.61, 7.61],
[1.17, 1.65, 1.61, 7.61]]),
array([0., 0., 0.]),
array([[1.],
[1.],
[1.]]),
('file_vel_16_loc_A.wav', 'file_vel_16_loc_A.wav', 'file_vel_16_loc_A.wav'),
array([206050, 206050, 206050]),
('vel_16_loc_A', 'vel_16_loc_A', 'vel_16_loc_A')]
]
Now, when I iterate through my batches each of the batches is a list. Length of the list is equal to the unique conditions found in the batch.
So basically what happens is:
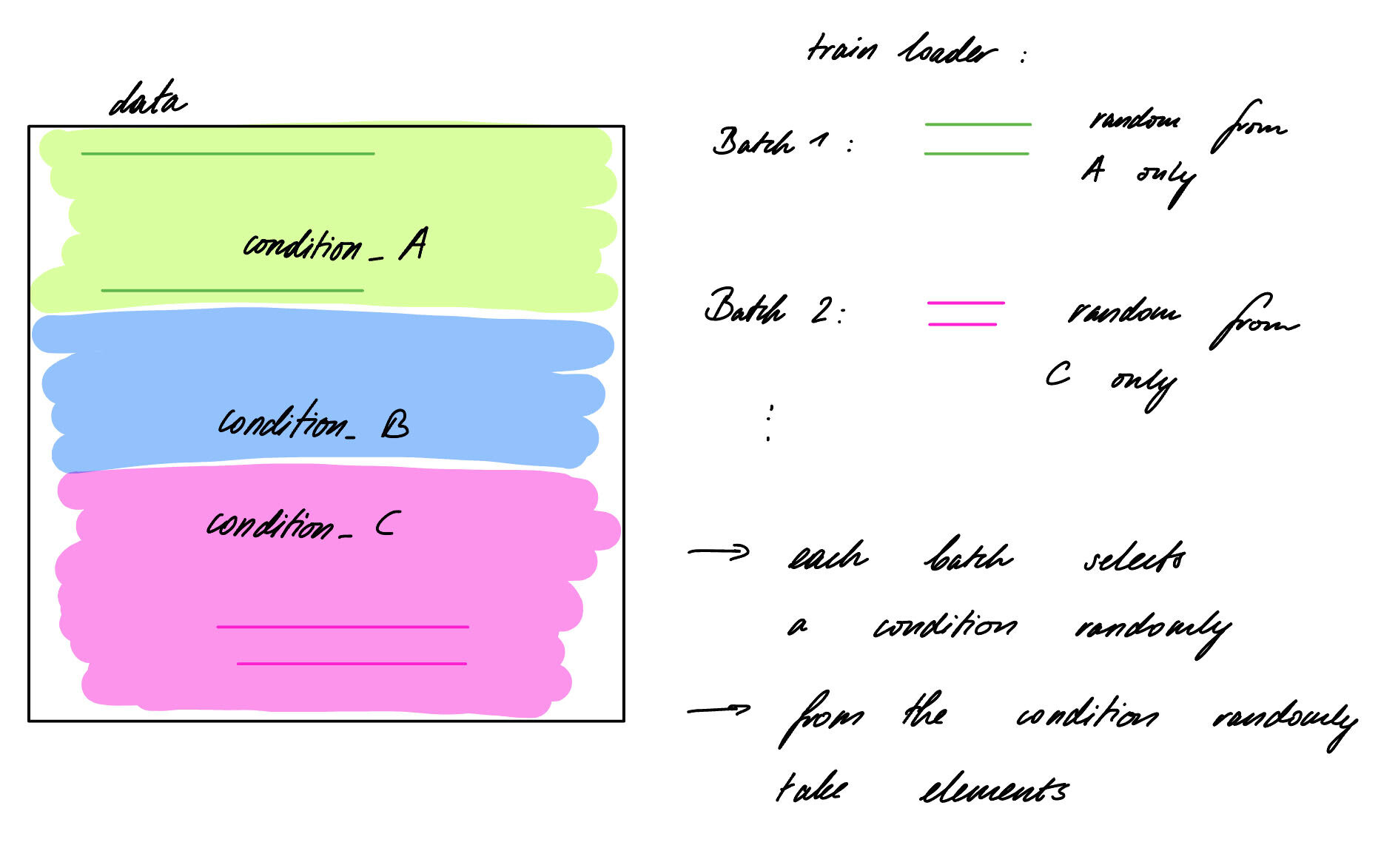
- A random batch is selected with batch size of e.g. 256
- This 256 samples are grouped based on their conditions. E.g. 50 samples in group A, 100 samples in group B, 106 samples in group C.
- Now I have three lists where I could pick some samples from
Unfortunately, it is not exactly what I would like.
If I transfer it to an stochastic urn model I would do the following, assuming I need a batch of 256 elements
- Pick first ball from the urn and note its color. E.g. red
- Pick further balls from the urn.
2a. If the ball is any different color, place it back in the urn
2b. If the ball is red add it to the sample.
- Repeat 2a and 2b until you have 256 red balls
From the documentation of the collate_fn I deduce, that this approach is NOT feasible, as collate_fn
comes into action after I have picked 256 random balls, and it just sorts them by color.
Can anybody suggest, how to model my problem in Torch?
In theory, I could just have arbitrary large batch sizes and then hope to get enough samples in the particular element of the list. But it is obviously hacky and unreliable.
I have implemented a dictionary of DataLoaders, each only for a specific condition. BUT for my model I would need always a batch from each condition where I know, that it is this particular condition and a random query, which might come from any of the potential conditions DataLoaders.
So if following the approach of condition specific DataLoaders, how do I ensure, that I actually processed through all of the samples with my random query?
In my toy example:
Imagine I have 3 conditions, each with 100 samples. So in total 300 samples. I wish to make 300 queries so each sample is definitely covered. And each of the samples will be compared with a randomly drawn sample from condition 1 only, condition 2 only, condition 3 only. So I will cycle 3 times through the condition specific DataLoader but only once through the general DataLoader.