I am currently working on implementing a Vision Transformer Architecture, which consists of a Shared Encoder and three Decoders for three different tasks, primarily focusing on white balancing. Each of these four components has been implemented as its own nn.Module.
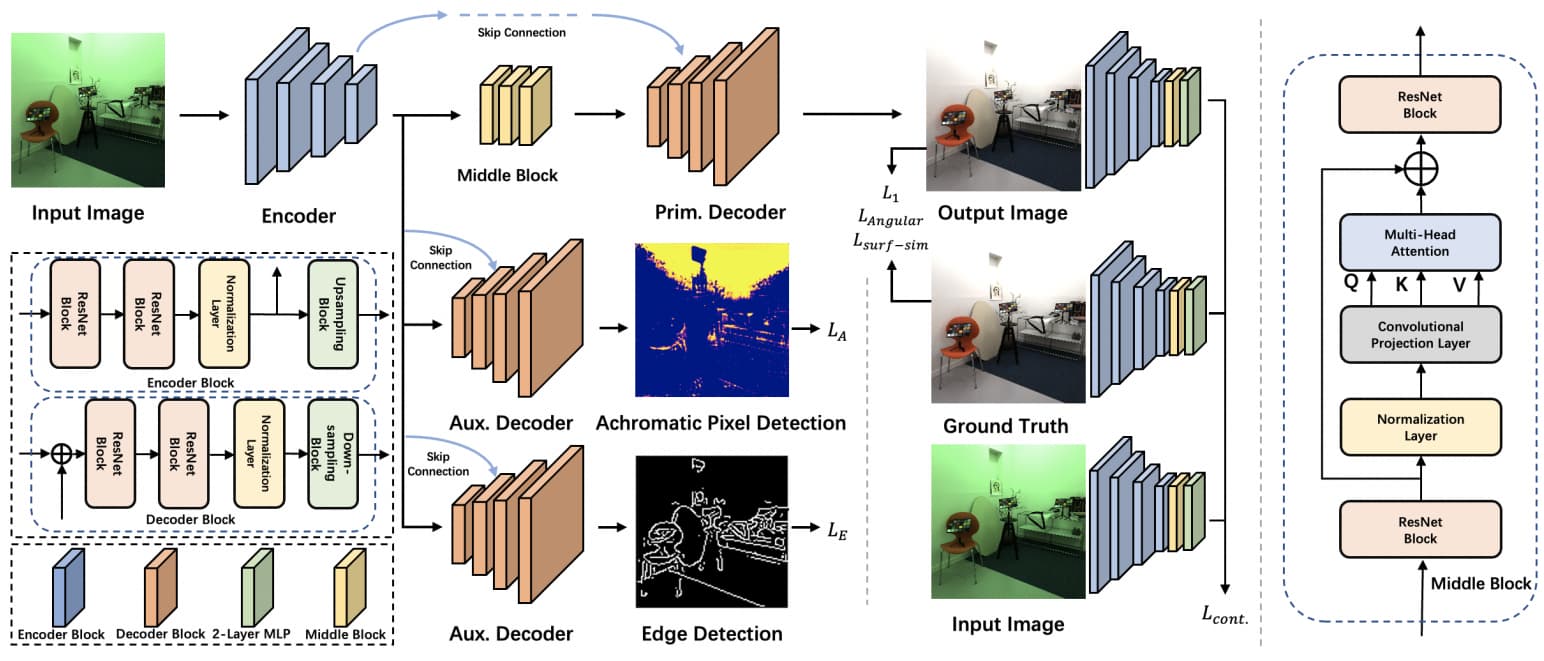
During the training phase, all four components are trained together. The Primary Decoder produces three separate losses (L1, L_ang, L_surf), while the two Auxiliary Decoders each have one loss (L_A and L_E). The loss of the Encoder should be the sum of these five losses (+ L_cont that I’ve not implemented yet).
My challenge lies in correctly backpropagating these losses and informing PyTorch which model each loss should be backpropagated to. Attempting to use multiple .backward() calls results in an error. I have come across suggestions to simply sum all the losses together, allowing the method to automatically handle the backpropagation. However, I do not fully understand this approach and I am unsure if it is effectively assigning the losses as intended.
Here is the code I am currently using for the backward pass within the Training function:
with torch.autocast(device.type if device.type != 'mps' else 'cpu', enabled=amp):
pred, achromatic_map, pred_hed = get_decoders_outputs(modules, *modules["encoder"](input))
total_loss = get_total_loss(input, pred, gt, achromatic_map, pred_hed, gt_hed, loss_weights)
# Loss
set_zero_grad(optimizers)
grad_scaler.scale(total_loss).backward()
update_modules(modules, optimizers, grad_scaler)
Additionally, here is the code for computing the losses:
def get_primary_loss(input, pred, gt, loss_weights):
loss_score = 0
loss_score += L1_loss(pred, gt, loss_weights[0])
loss_score += angular_loss(input, pred, gt, loss_weights[1])
loss_score += surf_loss(pred, gt, loss_weights[2])
return loss_score
def get_total_loss(input, pred, gt, achromatic_map, pred_hed, gt_hed, loss_weights):
primary_loss = get_primary_loss(input, pred, gt, loss_weights[2:5])
achromatic_loss = achromatic_pixel_detection_loss(gt, achromatic_map, loss_weights[0])
edge_loss = edge_detection_loss(pred_hed, gt_hed, loss_weights[1])
total_loss = primary_loss + edge_loss + achromatic_loss
return total_loss