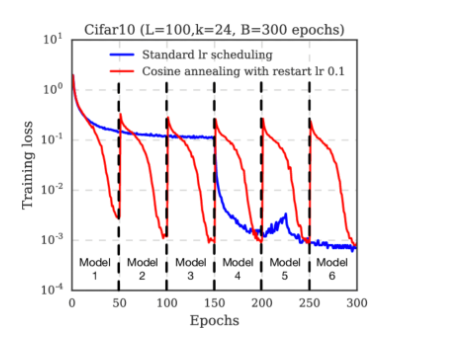
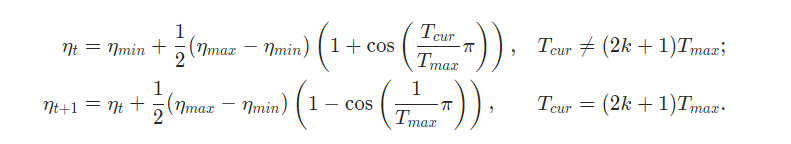Hi, guys. I am trying to replicate the torch.optim.lr_scheduler.CosineAnnealingLR. Which looks like:
However, if I implement the formula mentioned in the docs, which is:
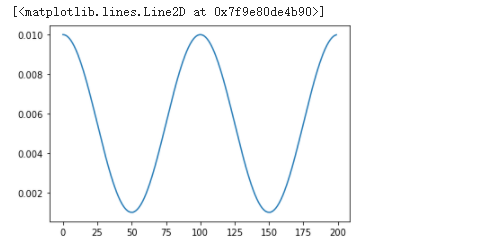
It is simply up-moved cosine function, instead of the truncated one above.
import numpy as np
from matplotlib import pyplot as plt
import math
lmin=0.001
lmax=0.01
tmax=50
x=[i for i in range(200)]
y=[lmin+0.5*(lmax-lmin)*(1+math.cos(i*math.pi/tmax)) for i in range(200)]
for i in range(200):
if (i/tmax)%2==1:
y[i+1]=y[i]+0.5*(lmax-lmin)*(1-math.cos(1/tmax))
# pass
plt.plot(x,y)
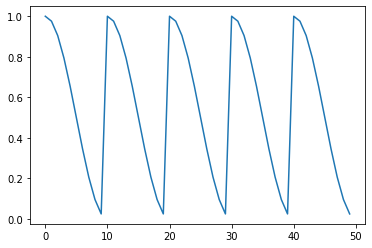
Thank you, Mr. Patrick. I finally figured out that T_cur represents the epochs since last restart, instead of the accumulated epochs. In my code,
y=[lmin+0.5*(lmax-lmin)*(1+math.cos(i*math.pi/tmax)) for i in range(200)]
should be changed to
y=[lmin+0.5*(lmax-lmin)*(1+math.cos((i%tmax)*math.pi/tmax)) for i in range(200)]
By the way, do you think it would be a good idea to gradually decay eta_max during training (maybe directly revert to the original eta_max might break the suboptimal to much)?