Hello,
I have defined a DenseNet (please follow the link for details) and a custom Loss-function MSE_mod as shown below:
# mean squared error with explicit const and linear terms
def MSE_toOptimize(params,yHat,y):
y0,y1 = params
x = [i for i in range(yHat.size()[1])]
x = torch.tensor(x).to('cuda:0')
size = yHat.size()[0]*yHat.size()[1]
diff = yHat + y0 + y1*x - y
res_ = torch.sum(diff**2) / size
return res_.cpu().detach().numpy()
def optimizedParametersAre(yHat,y):
guess = [0.,0.]
res = minimize(MSE_toOptimize, guess, args=(yHat,y))
params = res.x
return torch.tensor(params).to('cuda:0')
def MSE_mod(yHat,y):
params = optimizedParametersAre(yHat,y)
loss__ = MSE_toOptimize(params,yHat,y)
loss__ = torch.tensor(loss__).to('cuda:0').requires_grad_(True)
return loss__
This function MSE_mod integrates two other functions.
-
MSE_toOptimizeis the function bearing the expression for the Loss-function itself. As seen, the Loss-function is of the formsum((yHat + y0 + y1*x - y)**2), wherexis the vector of pixels, andy0andy1are parameters which are yet undefined. I want to have such values of these two parameters, so that the current expression for the Loss-function was minimized for givenyHatandy(yHatis the predicted vector, andyis the ground-truth vector). -
optimizedParametersAreis the function where the optimization takes place. This function returns the values ofy0andy1that minimize the Loss-function for given input vectorsyHatandy.
After training for a while (on a GPU) with such a Loss-function, I am getting the following results (the batch size is 100, the number of batches per epoch is 150):
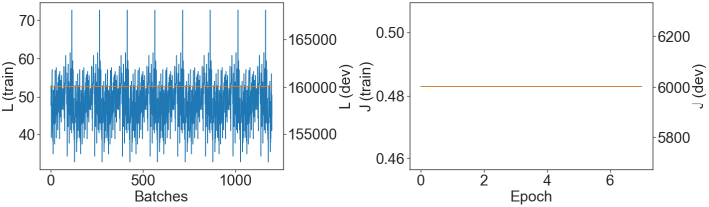
The L-labeled axis shows the actual values of this custom Loss-function for each of the consecutive batch, whereas J-labeled axis shows the overall cost-function defined as the normalized sum of all Loss-functions over one epoch (there are 7 epochs in total).
The question is why the Loss-values within an epoch repeat each other from one epoch to another without showing any evolution over epochs?