Hello, I am learning Pytorch and I have some codes to run on Fashion MNIST. But when I ran these codes:
def train(epoch):
model.train()
train_loss = 0
for data, label in train_loader:
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, label)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
for epoch in range(1, epochs+1):
train(epoch)
Someting wrong happened:
Could not load library libcudnn_cnn_train.so.8. Error: /usr/local/cuda-12.1/lib64/libcudnn_cnn_train.so.8: undefined symbol: _ZN5cudnn3cnn34layerNormFwd_execute_internal_implERKNS_7backend11VariantPackEP11CUstream_stRNS0_18LayerNormFwdParamsERKNS1_20NormForwardOperationEmb, version libcudnn_cnn_infer.so.8
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[17], line 2
1 for epoch in range(1, epochs+1):
----> 2 train(epoch)
3 val(epoch)
Cell In[15], line 9, in train(epoch)
7 output = model(data)
8 loss = criterion(output, label)
----> 9 loss.backward()
10 optimizer.step()
11 train_loss += loss.item()*data.size(0)
File ~/app/anaconda3/envs/pytorch-cuda12.1/lib/python3.10/site-packages/torch/_tensor.py:492, in Tensor.backward(self, gradient, retain_graph, create_graph, inputs)
482 if has_torch_function_unary(self):
483 return handle_torch_function(
484 Tensor.backward,
485 (self,),
(...)
490 inputs=inputs,
491 )
--> 492 torch.autograd.backward(
493 self, gradient, retain_graph, create_graph, inputs=inputs
494 )
File ~/app/anaconda3/envs/pytorch-cuda12.1/lib/python3.10/site-packages/torch/autograd/__init__.py:251, in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs)
246 retain_graph = create_graph
248 # The reason we repeat the same comment below is that
249 # some Python versions print out the first line of a multi-line function
250 # calls in the traceback and some print out the last line
--> 251 Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
252 tensors,
253 grad_tensors_,
254 retain_graph,
255 create_graph,
256 inputs,
257 allow_unreachable=True,
258 accumulate_grad=True,
259 )
RuntimeError: GET was unable to find an engine to execute this computation
my setting is:
- ubuntu 22.04
- Nvidia 1080ti * 4
- Nvidia driver version: 535.104.05
- cuda version(nvcc -V): 12.1
- torch version: 2.1.0
- torchaudio version: 2.1.0
- torchvision version: 0.16.0
- python version: 3.10.12
well, I am sure I have installed the cudnn, and I set the right LD_LIBRARY_PATH in the .bashrc
# cuda version change
export PATH=/usr/local/cuda-12.1/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH
Moreover, I can even see the libcudnn_cnn_train.so.8 right in the /usr/local/cuda-12.1/lib64, why can’t pytorch load it?
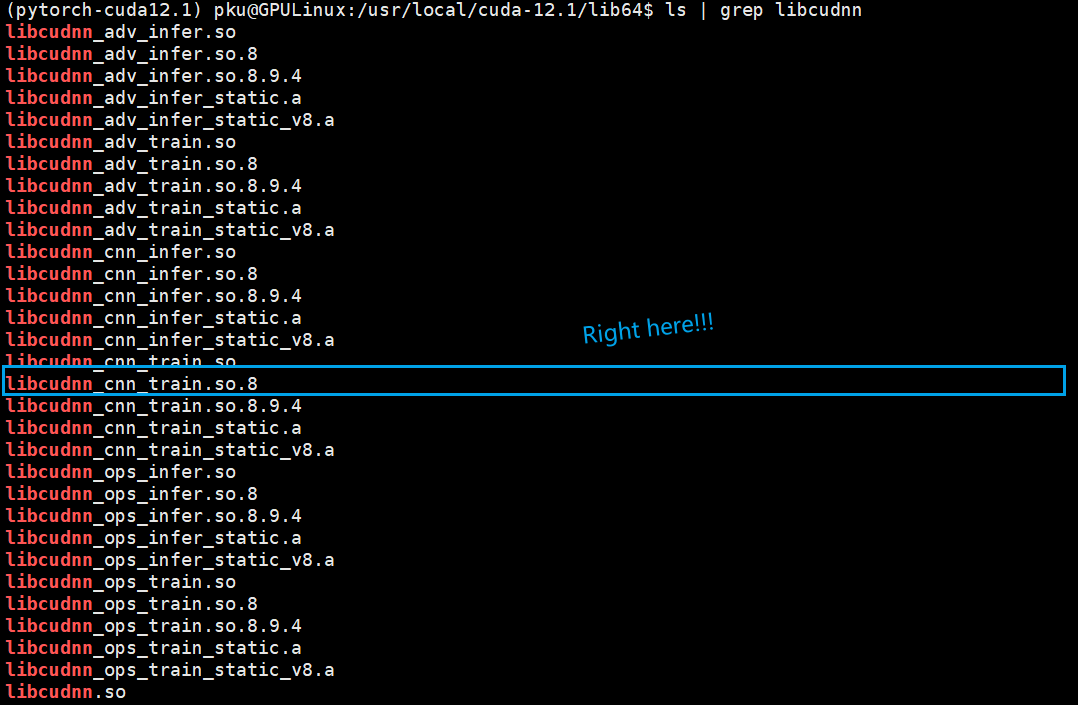
To make sure it’s not the case that I installed the cpuonly version pytorch, I did some test, and no problem.
import torch
print(torch.cuda.is_available())
print(torch.__version__)
print(torch.__path__)
print(torch.version.cuda)
# GPU
x = torch.randn(1, 3, 224, 224).cuda()
conv = torch.nn.Conv2d(3, 3, 3).cuda()
out = conv(x)
print(out.sum())
torch.backends.cudnn.version()
outcome:
True
2.1.0+cu121
['/home/pku/app/anaconda3/envs/pytorch-cuda12.1/lib/python3.10/site-packages/torch']
12.1
tensor(6512.6465, device='cuda:0', grad_fn=<SumBackward0>)
8904
Can you please help me with my problem?