I am trying to construct a network in paper SegMap: 3D Segment Mapping using Data-Driven Descriptors. When I ran my model, the loss didn’t change and was 7.542.
Here is the model’s structure:
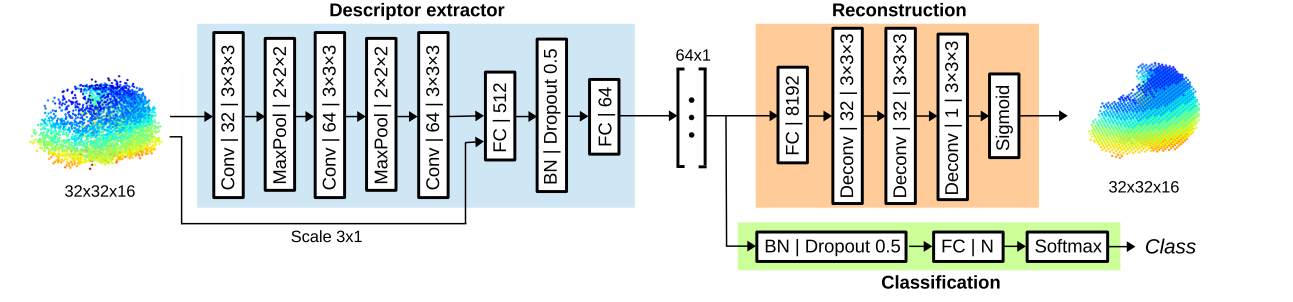
I am trying to construct the network in blue and green boxes.(the Descriptor extractor and Classification part).
Here is my code.
class SegMapNet(nn.Module):
def __init__(self, n_classes):
super(SegMapNet, self).__init__()
self.conv1 = nn.Conv3d(1, 32, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.pool1 = nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2))
self.conv2 = nn.Conv3d(32, 64, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.pool2 = nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2))
self.conv3 = nn.Conv3d(64, 64, kernel_size=(3, 3, 3), padding=(1, 1, 1))
self.fc1 = nn.Linear(64 * 8 * 8 * 4 + 3, 512)
self.bn1 = nn.BatchNorm1d(512, momentum=0.01)
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(512, 64)
self.bn2 = nn.BatchNorm1d(64, momentum=0.01)
self.fc3 = nn.Linear(64, n_classes)
self.relu = nn.ReLU()
self.softmax = nn.Softmax(dim=1)
# initialize_weights()
def forward(self, x, scale):
x = self.relu(self.conv1(x))
x = self.pool1(x)
x = self.relu(self.conv2(x))
x = self.pool2(x)
x = self.relu(self.conv3(x))
x = x.view(-1, 64 * 8 * 8 * 4)
x = torch.cat((x, scale), 1)
x = self.bn1(self.relu(self.fc1(x)))
x = self.dropout(x)
x = self.relu(self.fc2(x))
x = self.bn2(x)
x = self.dropout(x)
x = self.fc3(x)
x = self.softmax(x)
return x
def initialize_weights(self):
# print(self.modules())
nn.init.xavier_uniform_(self.conv1.weight)
nn.init.xavier_uniform_(self.conv2.weight)
nn.init.xavier_uniform_(self.conv3.weight)
nn.init.xavier_uniform_(self.fc1.weight)
nn.init.xavier_uniform_(self.fc2.weight)
nn.init.xavier_uniform_(self.fc3.weight)
And this is my training process:
for epoch in range(2):
running_loss = 0.0
np.random.shuffle(batches)
for step, train in enumerate(batches):
optimizer.zero_grad()
batch_segments, batch_classes = gen_train.next()
if batch_segments.shape[0] == 1:
# only have one sample in a batch
continue
batch_segments = torch.from_numpy(batch_segments).to(device)
batch_segments.requires_grad = True
batch_classes = torch.from_numpy(batch_classes).to(device)
scales_torch = torch.from_numpy(np.array(preprocessor.last_scales)).to(device)
scales_torch.requires_grad = True
output = segmap_net(batch_segments.float(), scales_torch.float())
## disp accuracy
correct = 0
predict_classes = torch.argmax(output, 1)
for i in range(predict_classes.size()[0]):
if predict_classes[i] == batch_classes[i]:
correct = correct + 1
print('correct: %d' % correct)
##
loss = criterion(output, batch_classes)
loss.backward()
# print(segmap_net.fc2.weight)
optimizer.step()
# print(segmap_net.fc2.weight)
running_loss += loss.item()
# if step % 100 == 99: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, step + 1, running_loss))
running_loss = 0.0
Hope for anyone’s sugesstion!