The .data should not be necessary as you’re in a no_grad() block. Same for setting the paremeters not to require gradients.
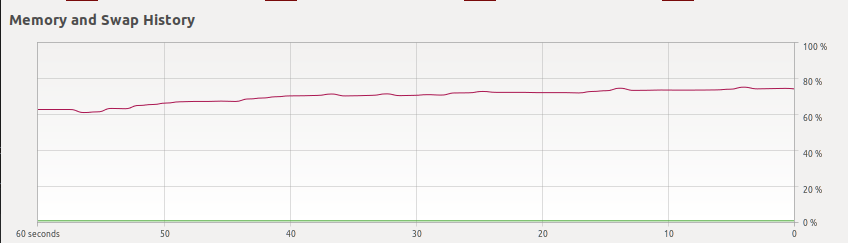
How do you measure memory usage?
Can you give a bit more context on your code? Does the model save some states by any chance?
Or do you save some outputs for later processing?
I removed t".data" and requires_grad = False. No change.
I am measuring memory using ubuntu’s “system monitor” and glances.
I don’t think my code has any states. It has a couple of static variables other than nn.modules.
The model is mostly sequential convolutions, normalizations, multiplications, sums…etc. Nothing too crazy. It’s not an ensemble or GAN or anything like that.
When training I was using a GPU and it would run iterations including validations for days without issues.
Replace your actual dataset with a bunch of input = torch.rand(some_hardcoded_size) inside the evaluation loop
Remove your instrumentation code (evaluating the accuracy / plotting etc)
Replace your model with a randomly initialized version (don’t load the state dict)
Replace your model with a single Linear layer that perform the mapping you want (with some views maybe)
Change the input/output sizes so that tests run quickly
At each step when you remove something, make sure that the memory behavior is still bad.
Let me know how far you can get. I may be able to look at your code but if it is big, it might take some time to reproduce / pinpoint the problem with the above process as I won’t be familiar with the code.
Well this is embarrassing but it really seems to not be the fault of pytorch. If I run random inputs with constant size directly through the net it doesn’t increase the ram. I still haven’t found the real issue so I’ll keep this open incase it turns out to be some weird combination of things that include the net.
Thanks!
So after some more debugging I found that if I switch to pytorch cpu the ram stays stable.
So it looks like it was a pytorch related bug after all. None the less I loved your keep it simple stupid debugging methods. I think i’ll hang them up on the wall.