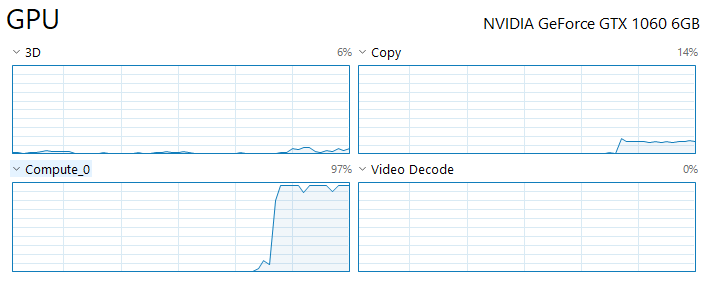
I have a CUDA supported GPU (Nvidia GeForce GTX 1070) and I have installed both of the CUDA (version 10) and the CUDA-supported version of PyTorch.
Despite my GPU is detected, and I have moved all the tensors to GPU, my CPU is used instead of GPU as I see almost no GPU usage when I monitor it.
Here is the code:
num_epochs = 10
batch_size = 20
learning_rate = 0.0001
log_interval = 50
class AndroModel(torch.nn.Module):
def __init__(self, input_size):
super(AndroModel, self).__init__()
self.kernel_size = 3
self.padding = 0
self.stride = 1
self.input_size = input_size
self.conv1 = nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=16, kernel_size=self.kernel_size, padding=self.padding,
stride=self.stride, bias=False),
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv1d(in_channels=16, out_channels=32, kernel_size=self.kernel_size, padding=self.padding,
stride=self.stride, bias=False),
nn.ReLU(inplace=True)
)
self.conv3 = nn.Sequential(
nn.Conv1d(in_channels=32, out_channels=64, kernel_size=self.kernel_size, padding=self.padding,
stride=self.stride, bias=False),
nn.ReLU(inplace=True)
)
self.conv4 = nn.Sequential(
nn.Conv1d(in_channels=64, out_channels=128, kernel_size=self.kernel_size, padding=self.padding,
stride=self.stride, bias=False),
nn.ReLU(inplace=True)
)
self.conv5 = nn.Sequential(
nn.Conv1d(in_channels=128, out_channels=256, kernel_size=self.kernel_size, padding=self.padding,
stride=self.stride, bias=False),
nn.ReLU(inplace=True)
)
self.num_conv_layers = 5
last_conv_layer = self.conv5
new_input_size = self.calculate_new_width(self.input_size, self.kernel_size, self.padding, self.stride, self.num_conv_layers, max_pooling=None)
out_channels = last_conv_layer._modules['0'].out_channels
dimension = out_channels * new_input_size
self.fc1 = nn.Sequential(
nn.Linear(in_features=dimension, out_features=3584),
nn.Dropout(0.5))
self.fc2 = nn.Sequential(
nn.Linear(in_features=3584, out_features=1792),
nn.Dropout(0.5))
self.fc3 = nn.Sequential(
nn.Linear(in_features=1792, out_features=448),
nn.Dropout(0.5))
self.fc4 = nn.Sequential(
nn.Linear(in_features=448, out_features=112),
nn.Dropout(0.5))
self.fc5 = nn.Sequential(
nn.Linear(in_features=112, out_features=28),
nn.Dropout(0.5))
self.fc6 = nn.Sequential(
nn.Linear(in_features=28, out_features=6),
nn.Dropout(0.5))
self.fc7 = nn.Sequential(
nn.Linear(in_features=6, out_features=2))
def forward(self, x):
x = x.reshape((-1, 1, self.input_size))
output = self.conv1(x)
output = self.conv2(output)
output = self.conv3(output)
output = self.conv4(output)
output = self.conv5(output)
output = output.view(output.size(0), -1)
output = self.fc1(output)
output = self.fc2(output)
output = self.fc3(output)
output = self.fc4(output)
output = self.fc5(output)
output = self.fc6(output)
output = self.fc7(output)
return output
@staticmethod
def calculate_new_width(input_size, kernel_size, padding, stride, num_conv_layers, max_pooling=2):
new_input_size = input_size
for i in range(num_conv_layers):
new_input_size = ((new_input_size - kernel_size + 2 * padding) // stride) + 1
if max_pooling is not None:
new_input_size //= max_pooling
return new_input_size
class AndroDataset(Dataset):
def __init__(self, features_as_ndarray, classes_as_ndarray):
self.features = torch.from_numpy(features_as_ndarray).float().to(device)
self.classes = torch.from_numpy(classes_as_ndarray).float().to(device)
def __getitem__(self, index):
return self.features[index], self.classes[index]
def __len__(self):
return len(self.features)
def main():
start = time()
global device
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('Device: {}'.format(device))
if torch.cuda.is_available():
print('GPU Model: {}'.format(torch.cuda.get_device_name(0)))
csv_data = pd.read_csv('android_binary.csv')
num_of_features = csv_data.shape[1] - 1
x = csv_data.iloc[:, :-1].values
y = csv_data.iloc[:, -1].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
training_data = AndroDataset(x_train, y_train)
test_data = AndroDataset(x_test, y_test)
print('\n~~~~~~~~ TRAINING HAS STARTED ~~~~~~~~')
print('# of training instances: {}'.format(len(training_data)))
train_loader = DataLoader(dataset=training_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_data, batch_size=batch_size, shuffle=True)
model = AndroModel(num_of_features)
model = model.to(device)
print('Model Overview:')
print(model, '\n')
criterion = nn.CrossEntropyLoss()
criterion = criterion.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
losses_in_epochs = []
# training
total_step = len(train_loader) # ayni zamanda VERI/BATCH_SIZE a esit
for epoch in range(num_epochs):
losses_in_current_epoch = []
for i, (features, classes) in enumerate(train_loader):
features, classes = features.to(device), classes.to(device, dtype=torch.int64)
optimizer.zero_grad()
output = model(features)
loss = criterion(output, classes)
loss.backward()
optimizer.step()
if (i + 1) % log_interval == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, num_epochs, i + 1, total_step,
loss.item()))
losses_in_current_epoch.append(loss.item())
avg_loss_current_epoch = 0
for tmp_loss in losses_in_current_epoch:
avg_loss_current_epoch += tmp_loss
avg_loss_current_epoch /= len(losses_in_current_epoch)
print('End of the epoch #{}, avg. loss: {:.4f}'.format(epoch + 1, avg_loss_current_epoch))
losses_in_epochs.append(avg_loss_current_epoch)
print('Average loss: {:.4f}'.format(losses_in_epochs[-1]))
print(f'Training Duration (in minutes): {(time() - start) / 60}')
print('\n~~~~~~~~ TEST HAS STARTED ~~~~~~~~')
print('# of test instances: {}'.format(len(test_data)))
# test
accuracy = 0
with torch.no_grad():
correct = 0
for features, classes in test_loader:
features, classes = features.to(device), classes.to(device, dtype=torch.int64)
output = model(features)
output = output.to(device)
_, predicted = torch.max(output.data, 1)
correct += (predicted == classes).sum().item()
accuracy = 100 * correct / len(test_loader.dataset)
print('Accuracy of the model on the {} test instances: {:.4f} %'.format(len(test_loader.dataset), accuracy))


 Finally, I’d like to ask a couple of questions if you do not mind:
Finally, I’d like to ask a couple of questions if you do not mind: