Hi Code : train_dataleak.py · GitHub
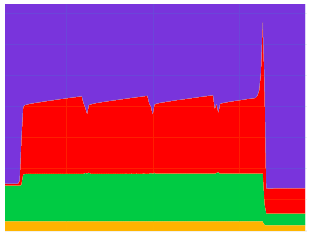
I observed that during training, things were fine until 5th epoch when the CPU usage suddenly shot up(see image for RAM usage).
I made sure that loss was detached before logging.
I observed that this does not happen if I comment out the loss.backward call(Line 181)
Finally I was able to get around by collected garbage using gc.collect() after every 50 batches.
But it still slows the epoch by a lot.
Some explanation for the code: Link to model code: I added some linear layers to a base model(VLBert) that was training without any issues. I do a forward pass for the base model, take an embedding from the output and pass it through the linear layers to produce 1 output.
The GPU(RTX 2080 TI) usage is not a problem, just the CPU usage. Printing out the tensors using gc.get_objects() as explained here shows there are no tensors on the CPU after every epoch.
What is the reason for garbage not being collected, any issues with the code?
This is very surprising that it only happens at the 5th epoch. Do you do anything specific at that time? because the print you shows seems to indicate a very different behavior.
Also are you using multiprocessing here? Does removing that helps?
What is the reason for garbage not being collected, any issues with the code?
The python garbage collector does not run very often. And in particular, if you don’t create objects fast, it might actually never run.
It is only useful to remove reference cycles so should not be needed in most cases.
Did you managed to get any insight of which objects get collected when you run this? Could it be some of the logging logic that creates these reference cycles?
Thanks for your response Alban.
I do not do anything specific at this time. I am using 8 GPUs with apex which uses multiprocessing I believe:
from apex.parallel import DistributedDataParallel as DDP
model = DDP(model, delay_allreduce=True)
optim = AdamW(model.parameters(), lr=args.learning_rate, correct_bias=False, eps=args.adam_epsilon)
model, optim = amp.initialize(model, optim, opt_level=args.opt_level, loss_scale=args.loss_scale,
keep_batchnorm_fp32=args.keep_batchnorm_fp32, verbosity=0)
Since it takes a lot more time to run 5 epochs without using the 8 GPUs, I haven’t run it that long to see if its resolved without using DDP.
Not sure if relevant and a source of reference cycles, I take a pre-trained base model and load its saved weights, and then initialise the weights for added layers.
Did you managed to get any insight of which objects get collected when you run this? Could it be some of the logging logic that creates these reference cycles?
In the code I shared, I do not see any source of reference cycles. I am simply logging losses with Tensorboard.
SInce removing .backward() does not lead to a leakage, I assumed that there are a few tensors on CPU that are in the computation graph. However upon printing out the tensors on all devices at different stages using this function, I found that there are some CPU tensors while batch is being processed in training (as received from dataloader before being moved to cuda in new variables eg - imgs = data["imgs"].cuda()). But printing out the tensors on CPU before the next training epoch, I did not find anything on CPU. Also number of tensors on CPU at start of each batch is the same.
I is hard to say what the issue is here as there are way too many things that come into play.
I think you want to try and simplify your code and reduce your model to have something that reproduces this fast and without using so many complex features.