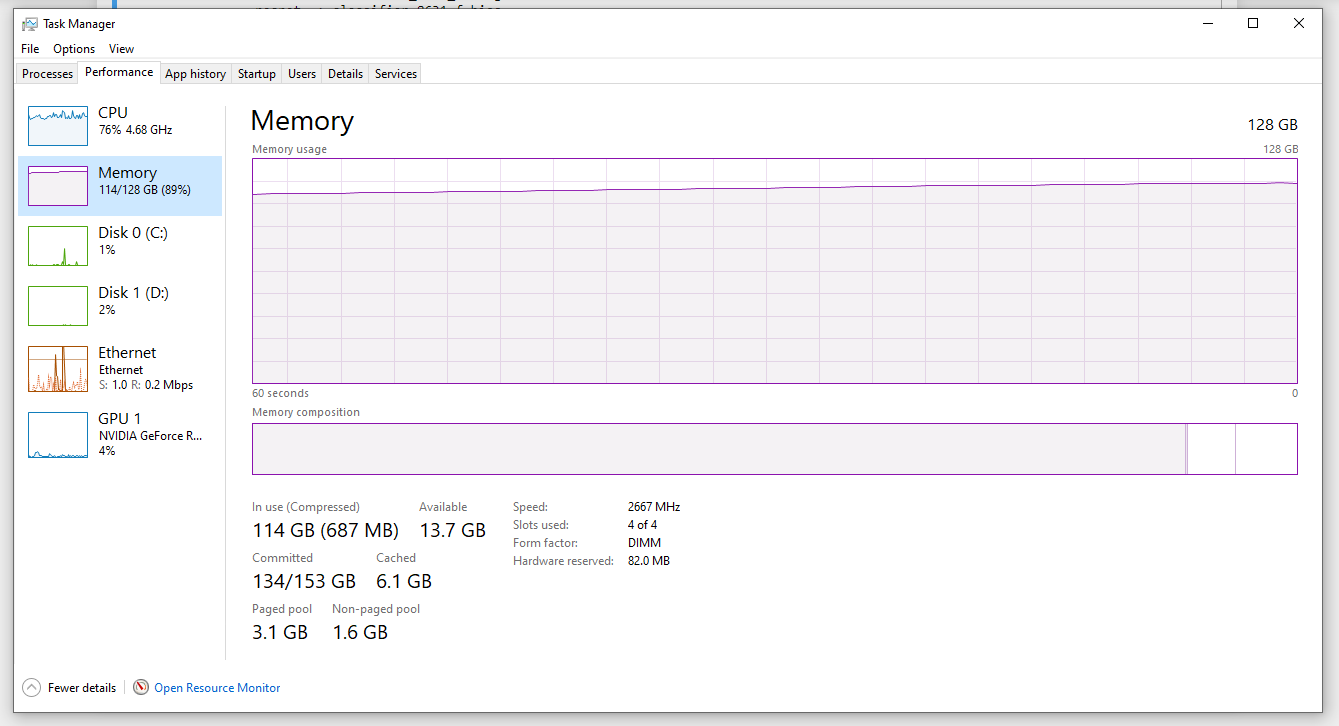
Hi. I failed to trace the reason why the CPU RAM usage increases after every iteration and exploded after some hundred of iterations.
I have replaced the loss += loss_batch with loss += loss_batch.detach().
Unfortunately, the CPU RAM problem remains the same.
My codes are as follows:
for batch_idx in range (iter_max):
lfw_lr_in, lfw_lr_in_aug_1, lfw_lr_in_aug_2 = next(lfw_loader)
lfw_lr_x, lfw_lr_y = lfw_lr_in
lfw_lr_x_aug_1, lfw_lr_y_aug_1 = lfw_lr_in_aug_1
lfw_lr_x_aug_2, lfw_lr_y_aug_2 = lfw_lr_in_aug_2
assert torch.all(torch.eq(lfw_lr_y, lfw_lr_y_aug_1))
assert torch.all(torch.eq(lfw_lr_y, lfw_lr_y_aug_2))
del lfw_lr_in, lfw_lr_in_aug_1, lfw_lr_in_aug_2
# ***
lfw_lr_x = lfw_lr_x.to(device)
lfw_lr_y = lfw_lr_y.to(device)
lfw_lr_emb = model(lfw_lr_x)
del lfw_lr_x
# ***
lfw_lr_x_aug_1 = lfw_lr_x_aug_1.to(device)
lfw_lr_y_aug_1 = lfw_lr_y_aug_1.to(device)
lfw_lr_emb_aug_1 = model(lfw_lr_x_aug_1)
del lfw_lr_x_aug_1
# ***
lfw_lr_x_aug_2 = lfw_lr_x_aug_2.to(device)
lfw_lr_y_aug_2 = lfw_lr_y_aug_2.to(device)
lfw_lr_emb_aug_2 = model(lfw_lr_x_aug_2)
del lfw_lr_x_aug_2
# ***
lfw_lr_emb = torch.cat((lfw_lr_emb, lfw_lr_emb_aug_1, lfw_lr_emb_aug_2), dim = 0)
lfw_lr_y = torch.cat((lfw_lr_y, lfw_lr_y_aug_1, lfw_lr_y_aug_2))
del lfw_lr_emb_aug_1, lfw_lr_y_aug_1
del lfw_lr_emb_aug_2, lfw_lr_y_aug_2
# *** ***
# Estimate lfw_loss_ce
lfw_loss_ce = 0
if net_params['lfw_fc_ce_flag'] is True:
lfw_lr_pred = lfw_fc(lfw_lr_emb, lfw_lr_y)
lfw_loss_ce = loss_fn['loss_ce'](lfw_lr_pred, lfw_lr_y)
del lfw_lr_emb, tf_lr_emb
# *** ***
# Define loss_batch
loss_batch = lfw_loss_ce
# *** ***
# if model.training:
optimizer.zero_grad()
loss_batch.backward()
optimizer.step()
time.sleep(0.0001)
# *** ***
metrics_batch = {}
for metric_name, metric_fn in batch_metrics.items():
metrics_batch[metric_name] = metric_fn(tf_lr_pred, tf_lr_y).detach().cpu()
metrics[metric_name] = metrics.get(metric_name, 0) + metrics_batch[metric_name]
if writer is not None: # and model.training:
if writer.iteration % writer.interval == 0:
writer.add_scalars('loss', {mode: loss_batch.detach().cpu()}, writer.iteration)
for metric_name, metric_batch in metrics_batch.items():
writer.add_scalars(metric_name, {mode: metric_batch}, writer.iteration)
writer.iteration += 1
#
#
# loss += loss_batch
loss += loss_batch.detach()
if show_running:
logger(loss, metrics, batch_idx)
else:
logger(loss_batch, metrics_batch, batch_idx)
gc.collect()
# END FOR
# *** ***
# if model.training and scheduler is not None:
if scheduler is not None:
scheduler.step()
loss = loss / (batch_idx + 1)
metrics = {k: v / (batch_idx + 1) for k, v in metrics.items()}
return metrics