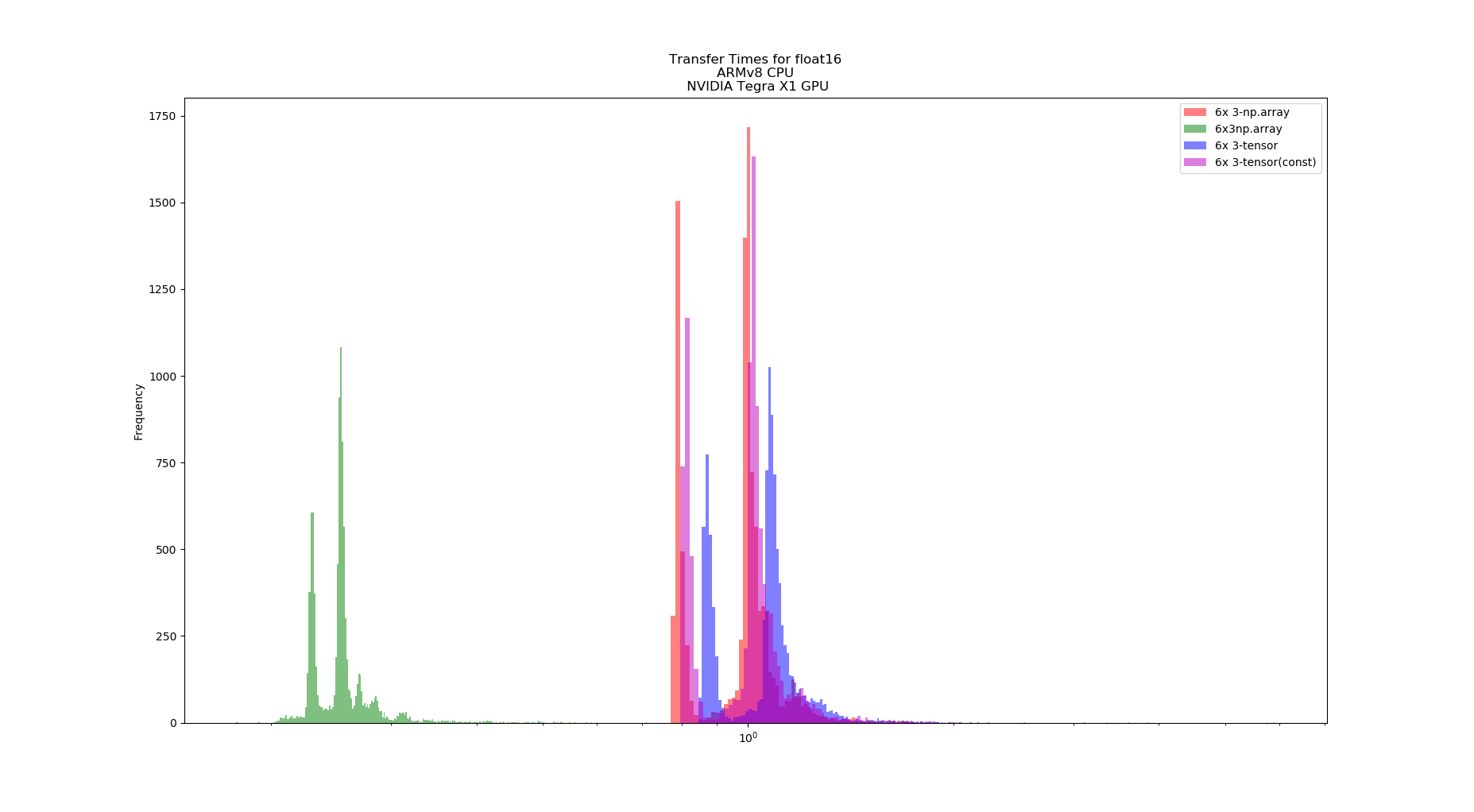
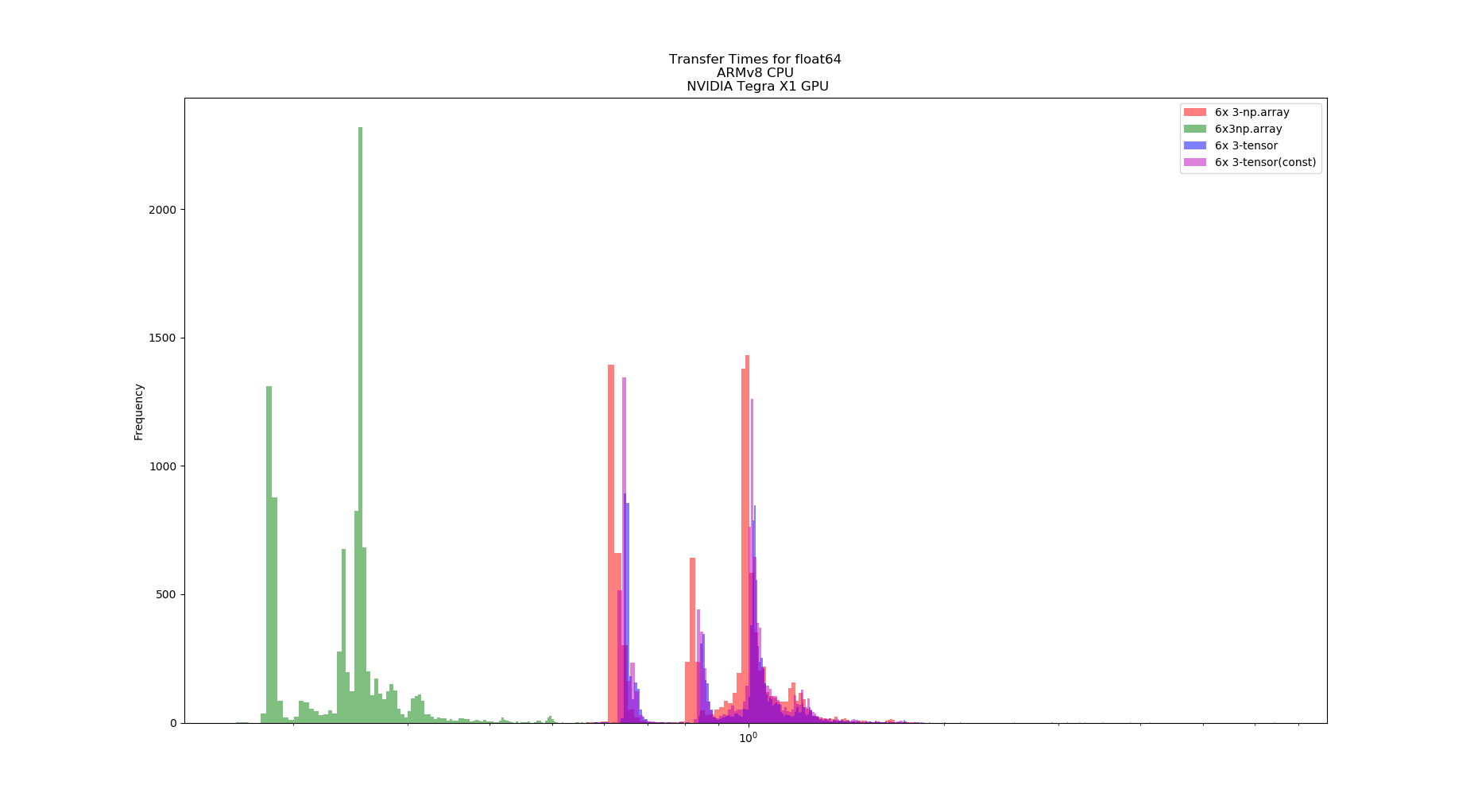
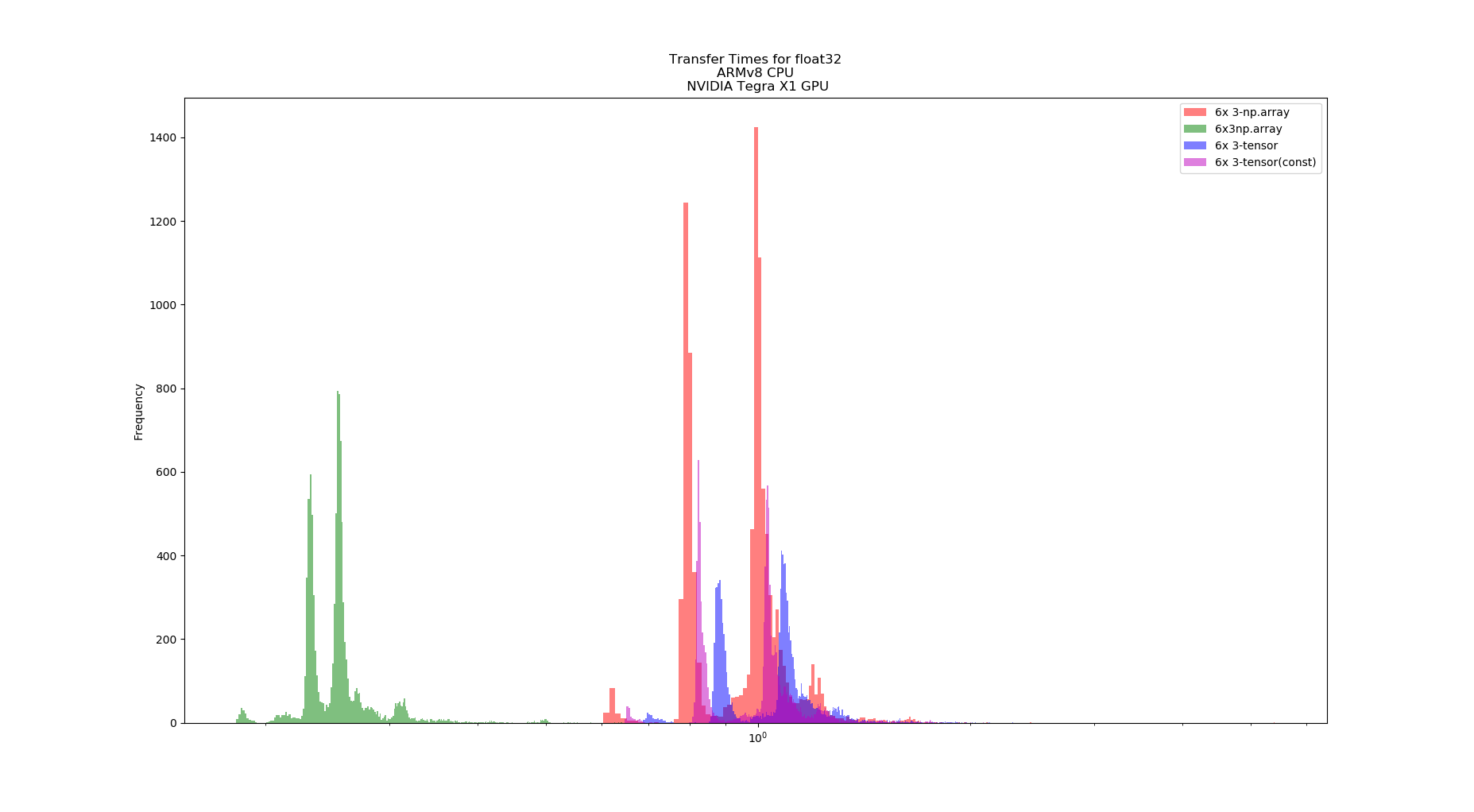
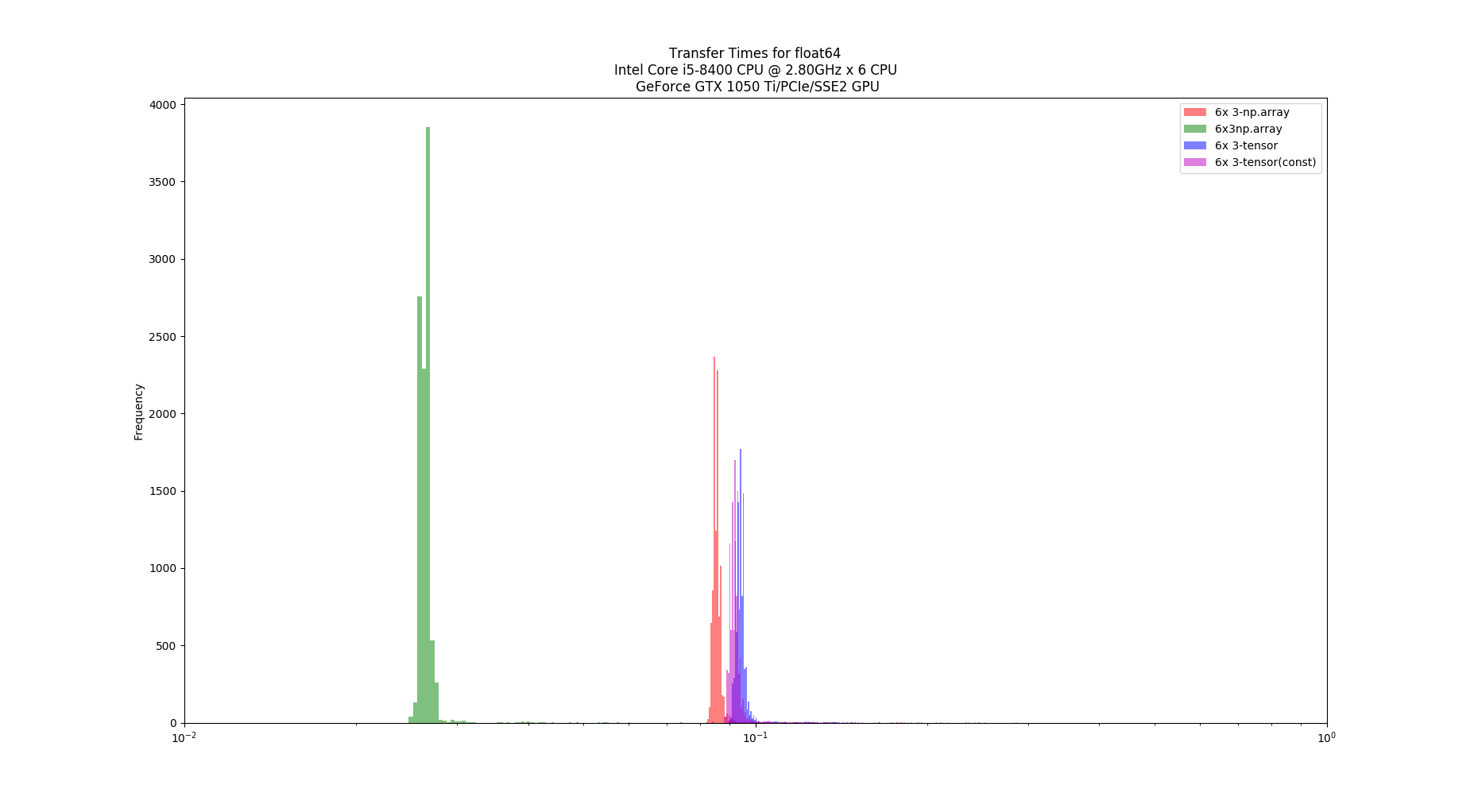
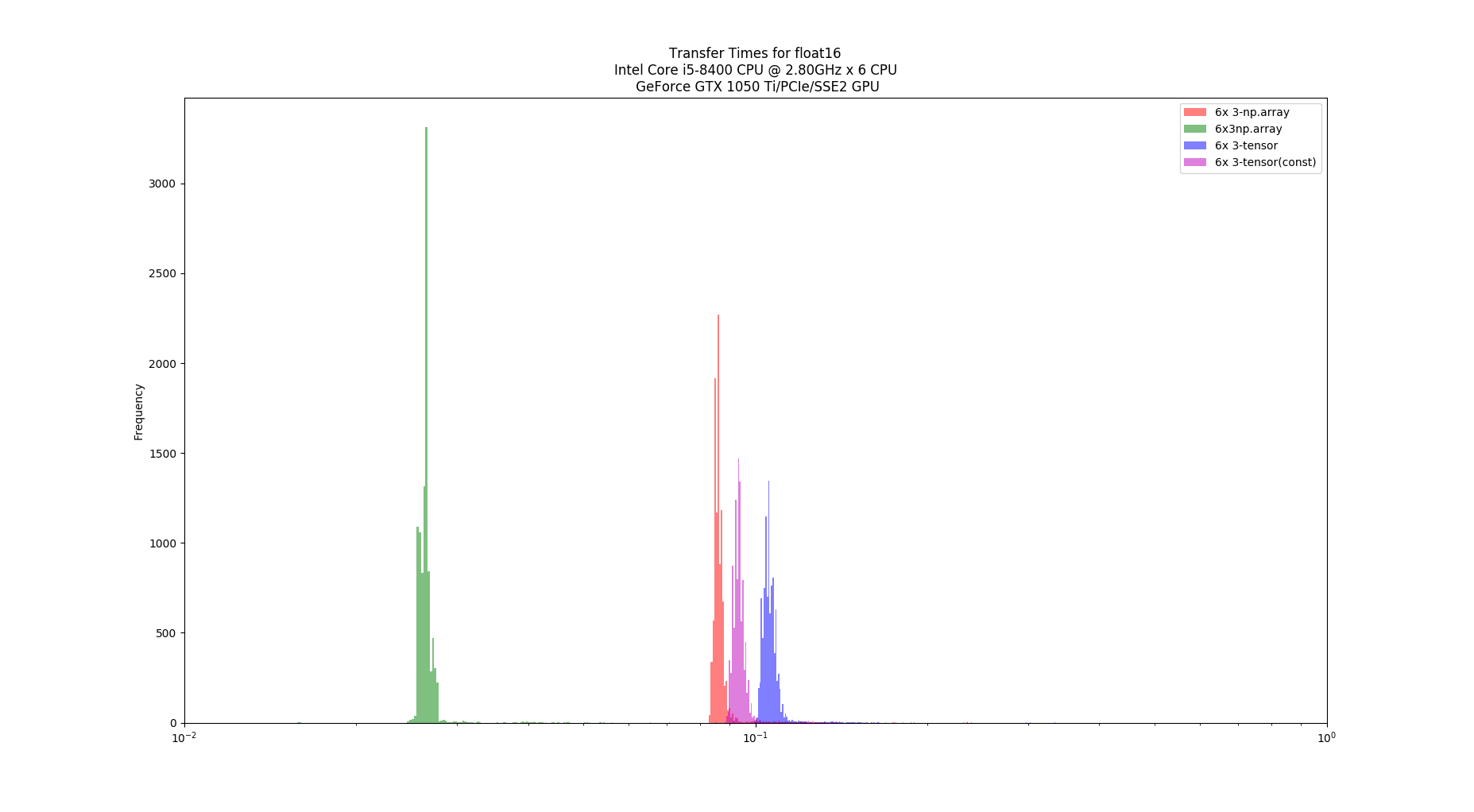
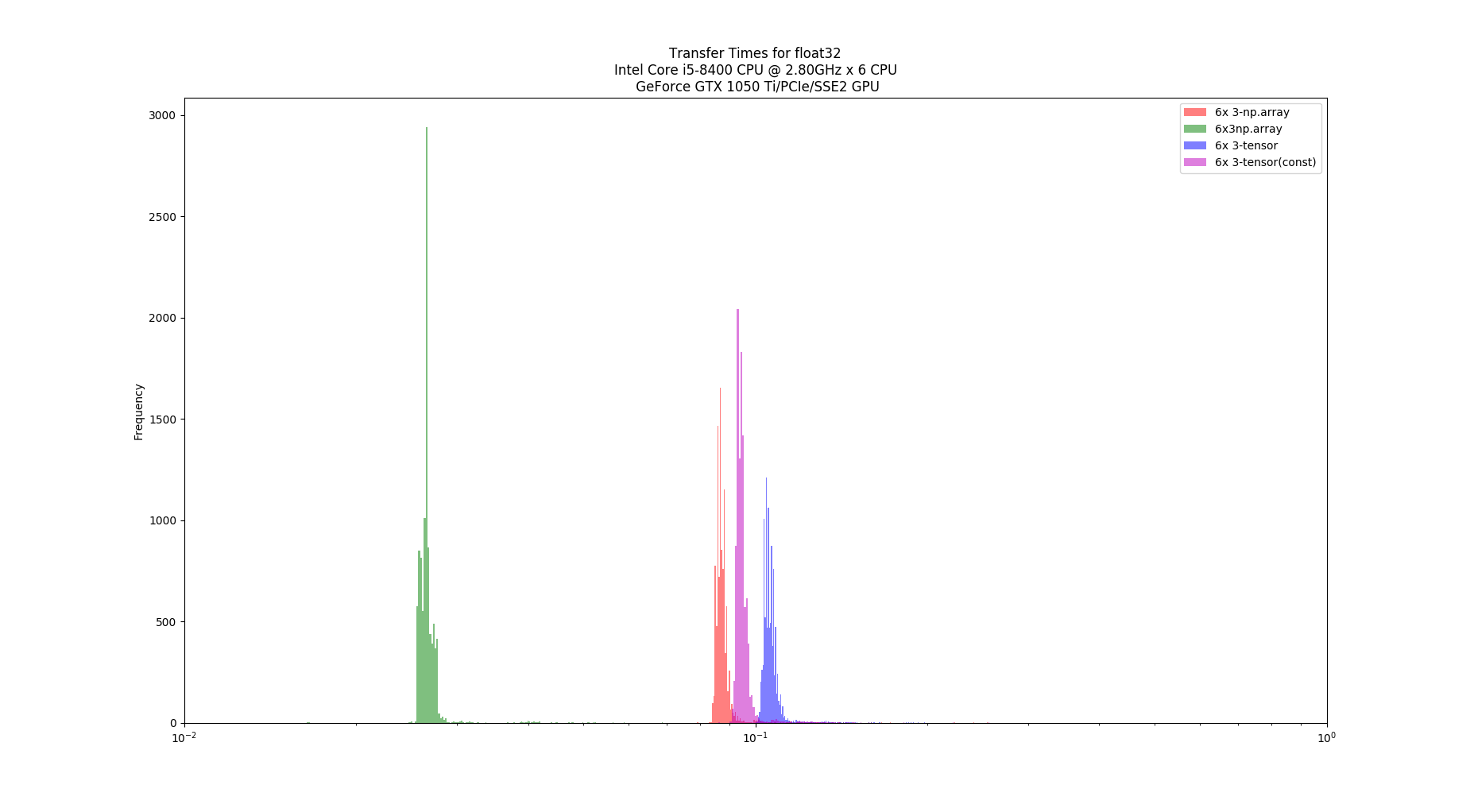
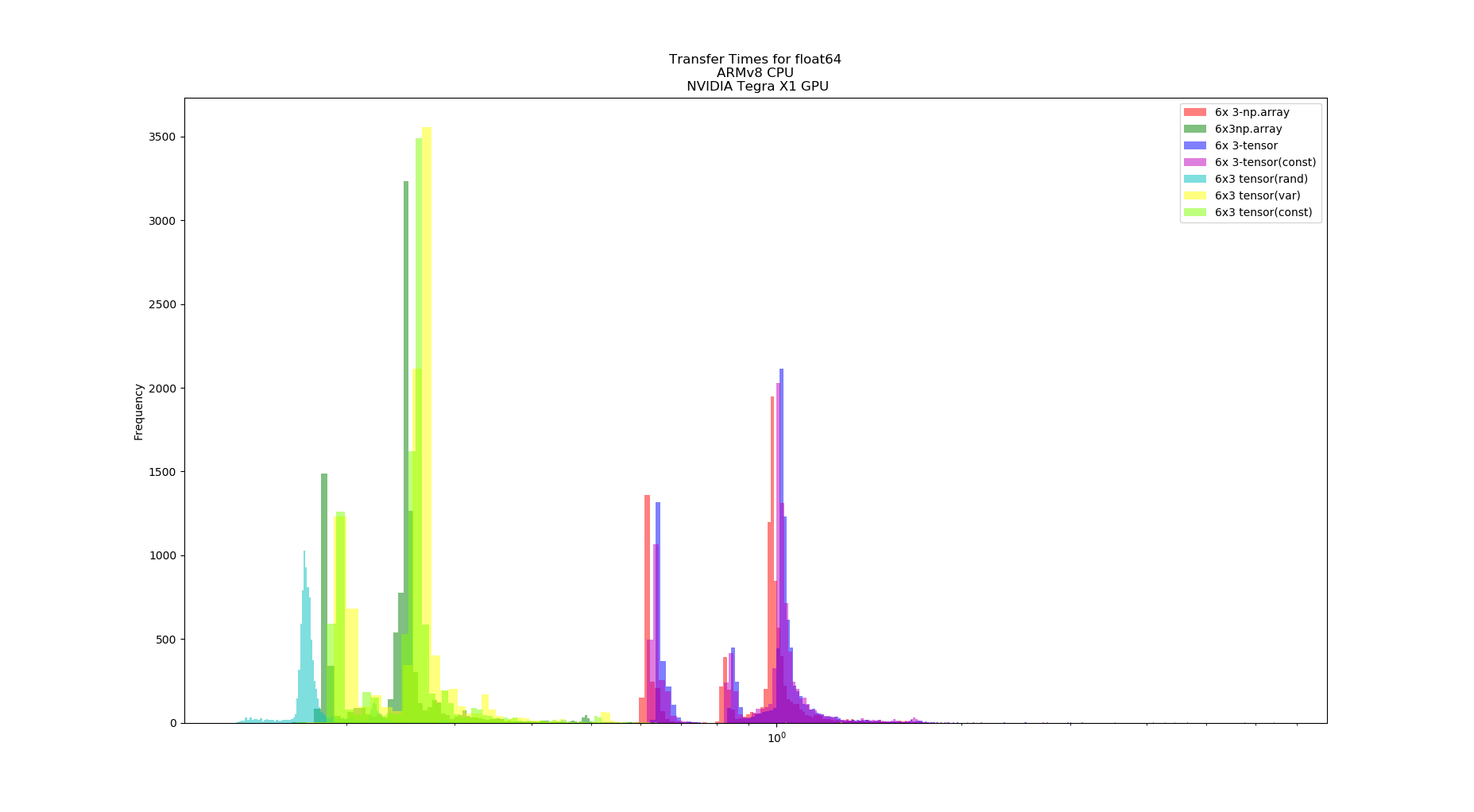
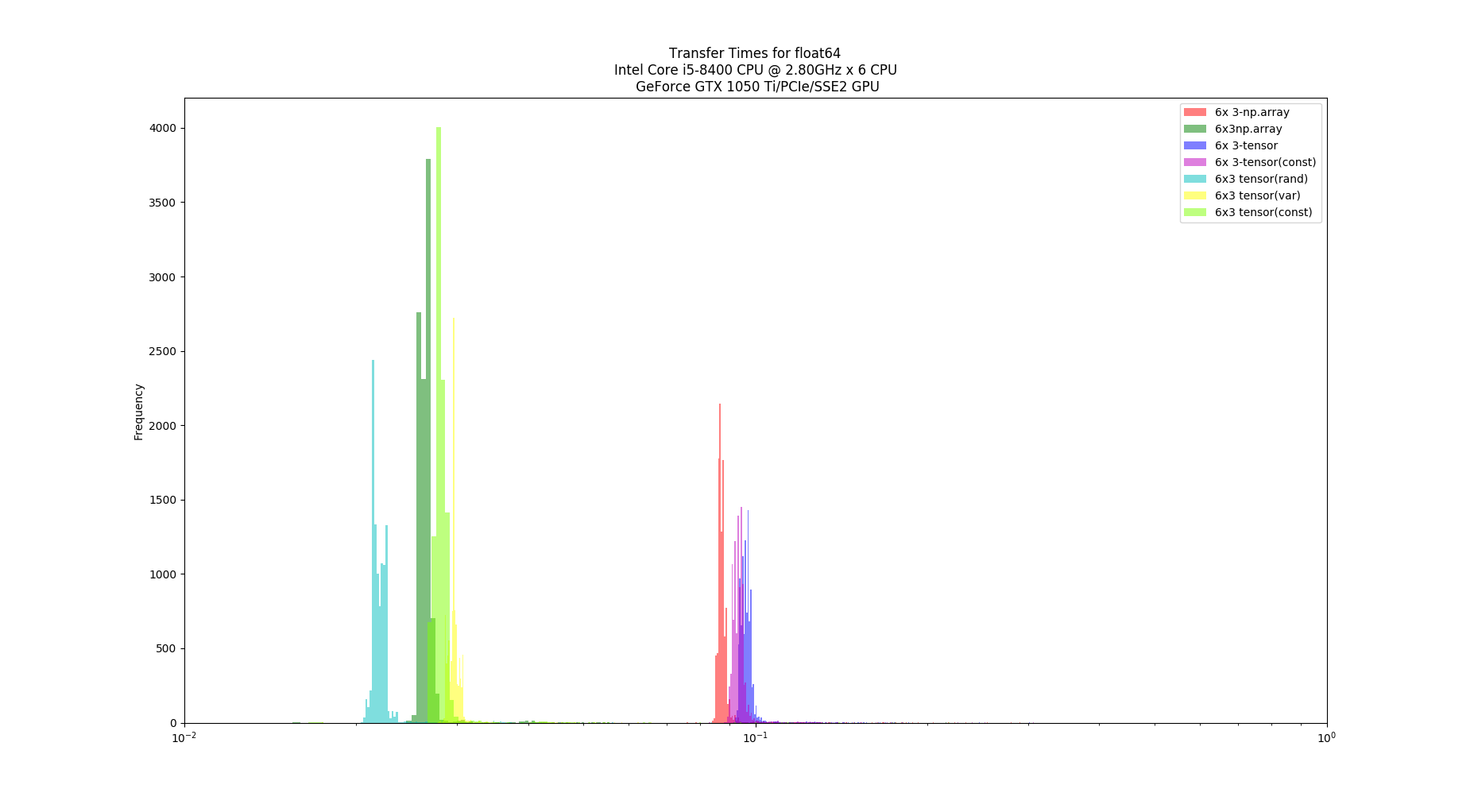
Hello,
I am coding a drone control algorithm (using modern control theory, not reinforcement learning) and was testing Pytorch as a replacement for Numpy. The algorithm receives as inputs the state of the drone and a desired trajectory, and computes the inputs for the drone to follow the trajectory. It must compute this at least at 100Hz.
The main purpose for trying Pytorch is to see if there would be any gains of using the GPU, since most of the operations are matrix-vector operations.
Links to source code of both controllers: numpy implementation, pytorch implementation and the script where I call each of them.
During my testing I found out that the same control algorithm written using numpy and running on the CPU is at least 10x faster than the pytorch implementation running on the GPU (using only torch functions). I tried both in a desktop computer and on a Jetson Nano with quite similar and interesting results:
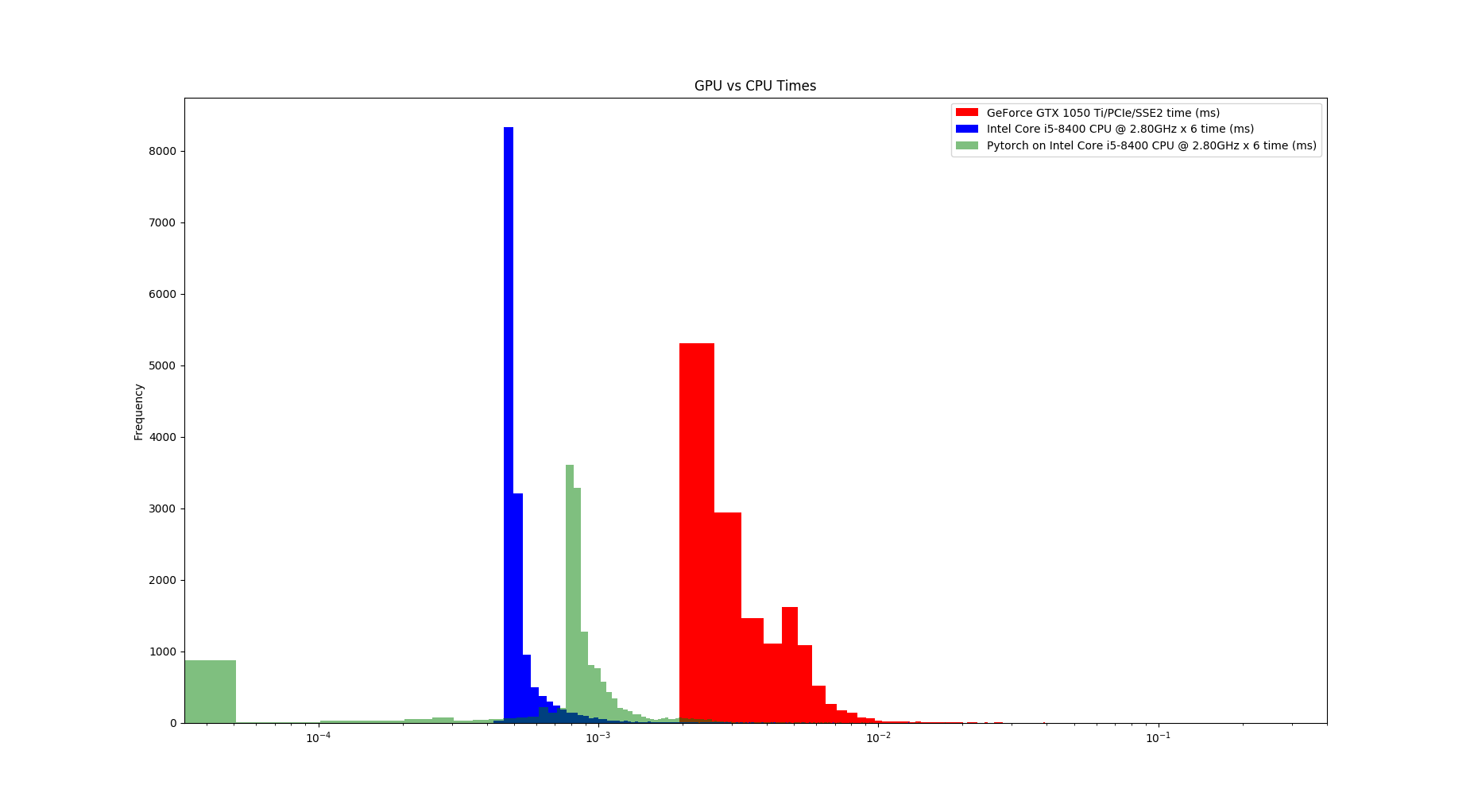
Two tests on desktop:
- Intel Core i5
- GeForce GTX 1050
- CUDA10
- Pytorch 1.2.

Two tests on Jetson Nano
- ARMv8
- Nvidia Tegra X1
- Pytorch 1.2
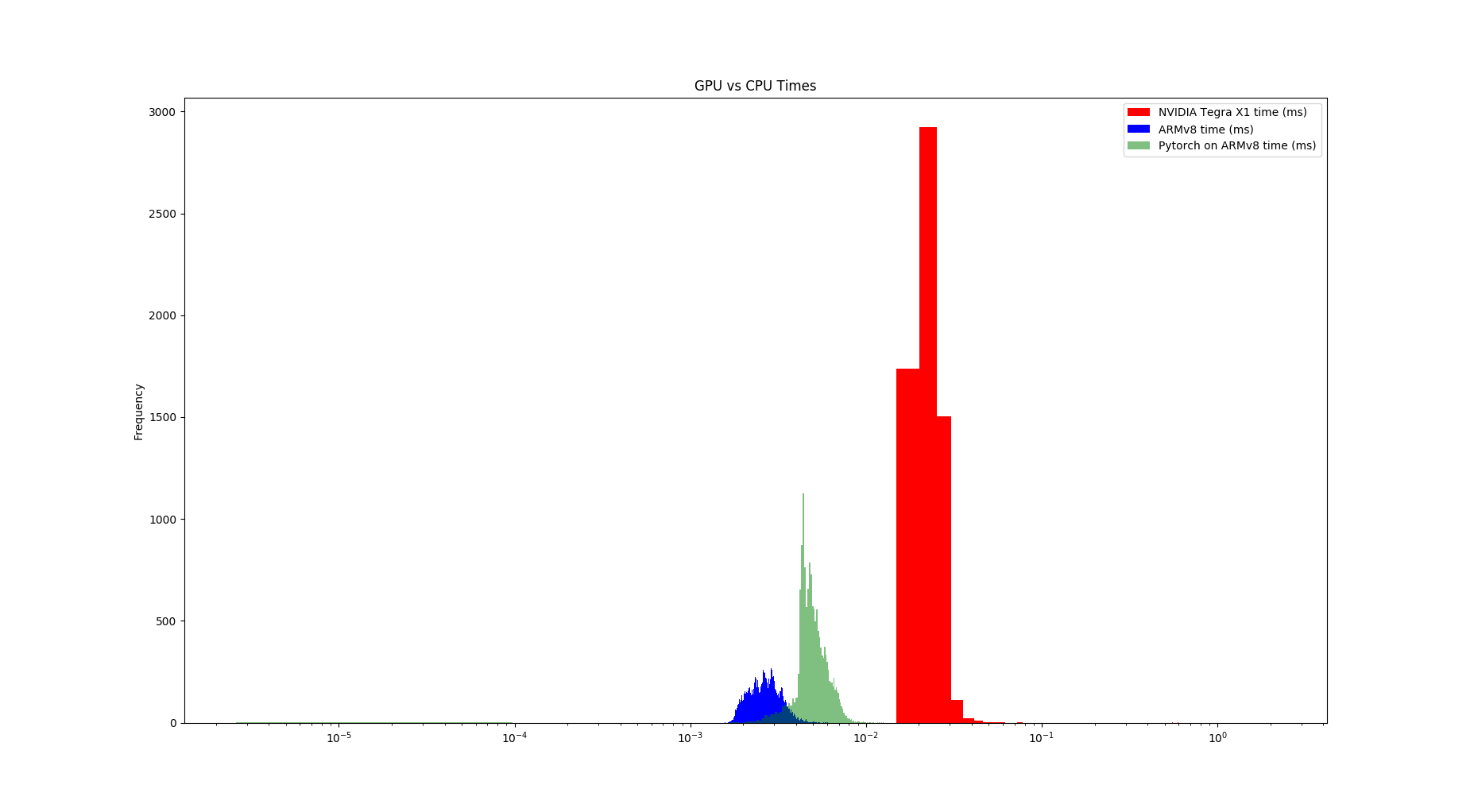

The graphs, one for each tests, shows the computation time distribution of the code running either on a)numpy on CPU (blue) b) Pytorch on CPU (green) and c) Pytorch on GPU (red)
In both hardware configurations, numpy on CPU was at least x10 faster that pytorch on GPU. Also, Pytorch on CPU is faster than on GPU. In the case of the desktop, Pytorch on CPU can be, on average, faster than numpy on CPU. Finally (and unluckily for me) Pytorch on GPU running in Jetson Nano cannot achieve 100Hz throughput.
What I am interested on is actually getting the Pytorch GPU on Jetson speed to reach a performance similar than its CPU speed on Jetson Nano (>=100Hz throughput), since I cannot attach a desktop to a drone.
Reading around it seems some issues could be
- Data transfer between CPU and GPU can be very expensive,
- Tensor type and dtype used
I am not sure how to dramatically improve from this. Currently all operations are done on Tensor.FloatTensor, and I load all the data to GPU at the beginning of each iteration, all computation gets done only on GPU, and I offload from GPU only at the end when all the results are ready.
I am aware this is not the main purpose for which pytorch was created but I would like to get advice on how to optimize the performance of Pytorch on GPU, on an smaller platform like Jetson Nano, and hopefully get a x10 increase in performance.
Any advice will be very welcome!
Juan
For reference, I measured executions times following:
For GPU:
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
# I put my code here
end.record()
torch.cuda.synchronize()
execution_time = start.elapsed_time(end)
For CPU:
start = time.time()
# I put my code here
end = time.time()
execution_time = end - start