If anybody has already read the paper or at first glance see answers for my questions, could i ask you for a small guidance? (if necessary i can provide the pdf)
My questions:
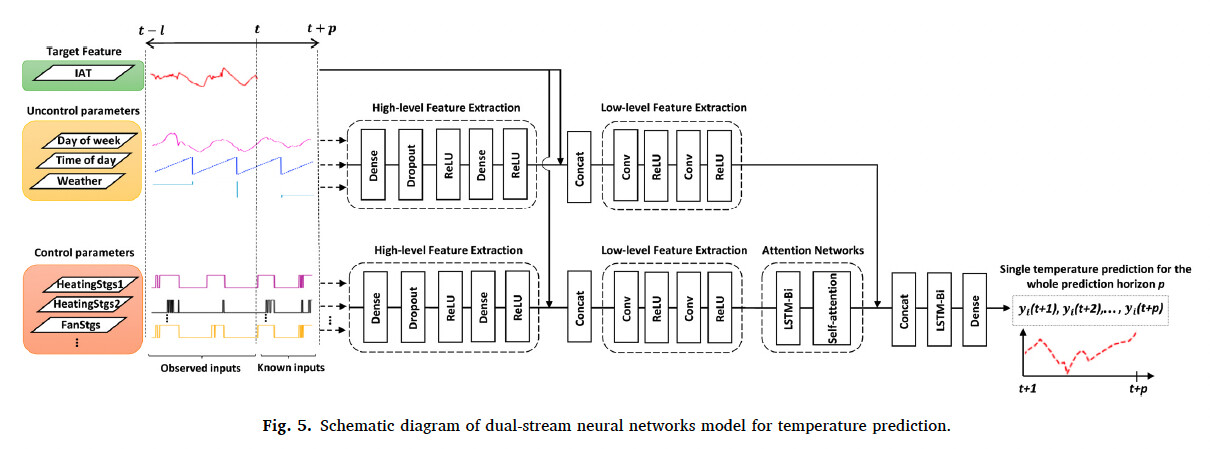
I am not sure about the concatenation, how it is meant. I mean if i have the data lets say till (t+l) and only temperature till (t), how can i concatenate them
Typically in time series forecasting, we also use lags, but from the paper, they only use t-1 value at thats it?
Thanks for any help or any suggestions, where to look for my questions.
According to the model chart, you’re concatenating the “Uncontrolled Features”(UF) and “Controlled Features”(CF) from t with the sequence data of the “Target Feature”(TF), but from t - 1(i.e. the last IAD settings used). With the goal of predicting the temperature at t + 1. From that, you can likely then calculate the current appropriate IAD settings(TF), such as cold, hot, or neutral.
For example, suppose all of the UF at t are concatenated on dim=1. So you’d have (batch_size, features_t) going into the first set of layers. Same for UC. Then just concat TF at t-1 to both of those, and the target value out is temperature at t+1.
Given the nature of the LSTM(being a recurrent network), the chart is just demonstrating how you go about passing in the data. The hidden layer, which gets passed back into each respective LSTM, will contain the relevant historical information for that sequence run(or should, after being trained sufficiently).
Answers to your questions:
I doubt they mean feed in t+1 values for UF and UC at time t. Seems they mean t values for UF/UC, and feed the t-1 TF value.
You’re giving the model the last settings used(i.e. the current state of the climate control system).
I was actually thinking about the same thing, but reading the paper again, it seems like they really predicted p time stemps ahead (which could be done with final layer of 12 neurons). But still, it seems to me, that they used the batch of data from t-l,…t (l is lookback window), which they fed into Dense layer,… then used CNN,… and then somehow flatten it and used into LSTM, otherwise, it just doesnt seems right only to use one time historical time stemp to predict p time stemps into the future. Honestly, the paper is nicely writte, but any references for pseudo code or something, and this high level explanation is just not enough,
Please review how LSTM layers work. They have a sequence dimension, so you can either do each step explicitly via a loop or pass it all in and let Pytorch do it under the hood(still via a loop).
I believe I know how the LSTM layer work (but thanks for explanation), but what i dont understand is, how they train the model. I think, what you mentioned in your first answer seems to be very logical, but I believe they really used some lookback window, and they fed matrix of feature inputs from t-l…t. But how can i process them like that, if the first layer is Dense l. (I mean, i could use batch, but then what). And also it seems like, it is multiple step prediction, but not done in a for loop, but really p prediction point at one time.