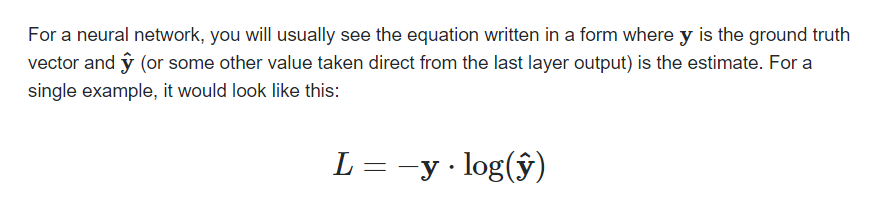I read the documentation for cross entropy loss, but could someone possibly give an alternative explanation? Or even walk through a small example of a 2x2 prediction and a 2x2 target. ie if target = [0,1;2,2] pred = [0,0;1,1] what would be the step by step be to calculate the cross entropy loss?
I’ve been having trouble finding an explanation relevant to semantic segmentation.
Here is a code snippet showing the PyTorch implementation and a manual approach.
Note that I’ve used for loops to show how this loss can be calculated and that the difference between a standard multi-class classification and a multi-class segmentation is just the usage of the loss calculation on each pixel. You should not use this code, as it’s way slower than the internal implementation (also the numerical stability is worse, as I haven’t used log_softmax):
# setup
criterion = nn.CrossEntropyLoss()
batch_size = 2
nb_classes = 4
output = torch.randn(batch_size, nb_classes)
target = torch.randint(0, nb_classes, (batch_size,))
loss = criterion(output, target)
# manual calculation
loss_manual = 0.
for idx in range(output.size(0)):
# get current logit from the batch
logit = output[idx]
# get target from the batch
t = target[idx]
loss_manual += -1. * logit[t] + torch.log(torch.sum(torch.exp(logit)))
# calculate mean loss
loss_elements = output.size(0)
loss_manual = loss_manual / loss_elements
print(torch.allclose(loss, loss_manual))
> True
# for segmentation
h, w = 4, 4
output = torch.randn(batch_size, nb_classes, h, w)
target = torch.randint(0, nb_classes, (batch_size, h, w,))
loss = criterion(output, target)
# manual calculation
loss_manual = 0.
for idx in range(output.size(0)):
for h_ in range(h):
for w_ in range(w):
# get current logit from the batch
logit = output[idx, :, h_, w_]
# get target from the batch
t = target[idx, h_, w_]
loss_manual += -1. * logit[t] + torch.log(torch.sum(torch.exp(logit)))
# calculate mean loss
loss_elements = (output.size(0) * output.size(2) * output.size(3))
loss_manual = loss_manual / loss_elements
print(torch.allclose(loss, loss_manual))
> True
Thank you for the thorough response. A few follow up questions:
What is the mean loss used for? Just to print out as the accuracy metric? The more specific loss values (not averaged) are used in backpropagation, correct?
For some reason my network is always preferring whatever is the first label in a muli-label segmentation… For example, If I were to be segmenting pixels as dog, cat, background, if the dox pixels were label ‘1’ in training, all would be classified as dog, but the same is true if I assigned cat to 1. I realize this is very unusual. Have you ever heard of something like this before?
No, the mean loss is used in the backward pass and thus to calculate the gradients. You are usually using the mean, since the sum of the loss would e.g. depend on the batch size and you would have to adapt the learning rate based on the batch size
No, haven’t heard it before and I would assume your model overfits to the majority class. Is this behavior reproducible, i.e. are you seeing the same “label preference” using different seeds?
Oh wow, for some reason I thought individual loss values (pixel/voxel-wise) were used, I thought the network would need more info about where specifically/on which labels things went wrong in the prediction which wouldn’t be encapsulated in the average. That is very good to know.
I also thought it was overfitting to majority class, but I swapped the labels every which way and no matter what it preferred label 1. I used https://github.com/wolny/pytorch-3dunet which is not my repo, and none of the examples include multi-class segmentation but it does support cross entropy loss so I’m not too sure.
The second issue is still interesting, as it smells a bit like a code bug.
Would you be able to write a code snippet to reproduce this issue (either with random data or with a torchvision dataset)?
Not necessarily, as the posted formula looks like the “positive” part of the binary cross-entropy loss.
Let me know, if you were able to create a code snippet to reproduce this issue.