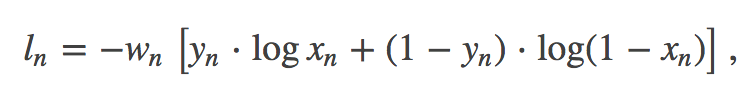That’s not what I mean. I need to pass one-hot vector, because later I want to use smoothed values as targets
(example [0.1, 0.1, 0.8]). max() won’t help here.
The first thing I want to achieve is to get the same results using CrossEntropyLoss() and some loss that takes one-hot encoded values without smoothing
nn.CrossEntropyLoss doesn’t take a one-hot vector, it takes class values. You can create a new function that wraps nn.CrossEntropyLoss, in the following manner:
Also I’m not sure I’m understanding what you want. nn.BCELossWithLogits and nn.CrossEntropyLoss are different in the docs; I’m not sure in what situation you would expect the same loss from them.
I want to use soft targets with Cross Entropy. Soft target is one-hot-like vector, but continuous, not zero/one. The example target is in the example code below.
This is what I want:
def cross_entropy(input, target, size_average=True):
""" Cross entropy that accepts soft targets
Args:
pred: predictions for neural network
targets: targets, can be soft
size_average: if false, sum is returned instead of mean
Examples::
input = torch.FloatTensor([[1.1, 2.8, 1.3], [1.1, 2.1, 4.8]])
input = torch.autograd.Variable(out, requires_grad=True)
target = torch.FloatTensor([[0.05, 0.9, 0.05], [0.05, 0.05, 0.9]])
target = torch.autograd.Variable(y1)
loss = cross_entropy(input, target)
loss.backward()
"""
logsoftmax = nn.LogSoftmax()
if size_average:
return torch.mean(torch.sum(-target * logsoftmax(input), dim=1))
else:
return torch.sum(torch.sum(-target * logsoftmax(input), dim=1))
i’m wondering if I can use any PyTorch function to pass soft targets to it, like in the example above. I was trying with BCELoss.
There’s no built in PyTorch function to do this right now, but you can use the cross_entropy function you defined and autograd will work with it. Are you finding that this function is too slow as it is?
# Calculating the loss
loss_val = nn.CrossEntropyLoss()(out, y) # (1)
loss_val1 = nn.BCEWithLogitsLoss()(out, y1) # (2)
If you’re referring to these, you definitely shouldn’t trust (1) because it doesn’t give you the behavior you want. (2) works, but has an extra term that may or may not affect your training.
hello. if the target label, i.e. y_n is the one-hot label, should it be the same with crossentropy loss? but why they result in different results in the examples?